Perimeter keamanan adalah seperangkat keamanan fisik dan kebijakan keamanan program yang memberikan tingkat perlindungan terhadap aktivitas berbahaya remote. Perimeter keamanan diberlakukan dalam bidang berikut:
Fisik Access Control. Perangkat keamanan dan kebijakan yang diberlakukan untuk kontrol akses fisik mencegah penyebaran virus melalui perangkat penyimpanan portabel, membantu melindungi data pada telepon dan Subscriber Identity Module (SIM).
Penandatanganan taksi.. . Taksi penandatanganan file menyediakan metode yang lebih aman dari kemasan dan memberikan aplikasi di Windows Mobile Standard. Dengan menandatangani. Taksi file untuk download, Windows Mobile Standard dapat memverifikasi sumber dan integritas file.
Manajemen perangkat. Kebijakan keamanan yang diterapkan untuk manajemen perangkat membantu melindungi perangkat dari ancaman yang mungkin berasal dari over-the-air (OTA) download atau pesan push.
Microsoft ® ActiveSync ®. Kebijakan RAPI yang diberlakukan untuk operasi ActiveSync membantu melindungi terhadap aplikasi-tingkat ancaman.
Routing adalah proses dimana suatu item dapat sampai ke tujuan dari satu lokasi ke lokasi lain. Beberapa contoh item yang dapat dirouting :mail, telepon call, dan data. Di dalam jaringan, Router adalah perangkat yang digunakan untuk melakukan routing trafik.
Untuk dapat me"routing" segala sesuatu, Router, atau segala sesuatu yang dapat melakukan fungsi routing, membutuhkan informasi sebagai berikut :
~ Alamat Tujuan/Destination Address - Tujuan atau alamat item yang akan dirouting
~ Mengenal sumber informasi - Dari mana sumber (router lain) yang dapat dipelajari oleh router dan memberikan jalur sampai ke tujuan.
~ Menemukan rute - Rute atau jalur mana yang mungkin diambil sampai ke tujuan.
~ Pemilihan rute - Rute yang terbaik yang diambil untuk sampai ke tujuan.
~ Menjaga informasi routing - Suatu cara untuk menjaga jalur sampai ke tujuan yang sudah diketahui dan paling sering terjadi.
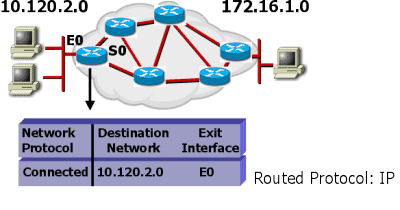
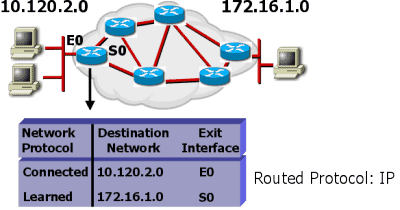
Tabel Routing
Sebuah router mempelajari informasi routing dari mana sumber dan tujuannya yang kemudian ditempatkan pada tabel routing .
Router akan berpatokan pada tabel ini, untuk memberitahu port yang akan digunakan untuk meneruskan paket ke alamat tujuan.
Jika jaringan tujuan tidak terhubung langsung di badan router, Router harus mempelajari rute terbaik yang akan digunakan untuk meneruskan paket. Informasi ini dapat dipelajari dengan cara :
Manual oleh "network administrator"
Pengumpulan informasi melalui proses dinamik dalam jaringan.
Jika jaringan tujuan, terhubung langsung (directly connected) di badan router, Router sudah langsung mengetahui port yang harus digunakan untuk meneruskan paket.
~ Routing adalah proses dimana suatu item dapat sampai ke tujuan dari satu lokasi ke lokasi lain. Untuk bisa me-routing, sebuah router harus tahu alamat tujuan, alamat asal/source, rute awal yang mungkin, dan path/jalur terbaik.
~ Informasi routing adalah router mempelajari, baik statik maupun dinamik, kemudian informasi tersebut ditempatkan dalam routing tabelnya.
~ Rute Statik adalah rute atau jalur spesifik yang ditentukan oleh user untuk meneruskan paket dari sumber ke tujuan. Rute ini ditentukan oleh administrator untuk mengontrol perilaku routing dari IP "internetwork".
~ Untuk mengkonfigurasi sebuah rute statik, masukkan perintah "ip route" dengan diikuti parameter: network, mask, address/alamat, interface, dan jarak/distance.
~ "Default route" adalah tipe rute statik khusus. Sebuah "default route" adalah rute yang digunakan ketika rute dari sumber/source ke tujuan tidak dikenali atau ketika tidak terdapat informasi yang cukup dalam tabel routing ke network tujuan.
Alamat IP (Internet Protocol Address atau sering disingkat IP) adalah deretan angka biner antar 32-bit sampai 128-bit yang dipakai sebagai alamat identifikasi untuk tiap komputer host dalam jaringan Internet. Panjang dari angka ini adalah 32-bit (untuk IPv4 atau IP versi 4), dan 128-bit (untuk IPv6 atau IP versi 6) yang menunjukkan alamat dari komputer tersebut pada jaringan Internet berbasis TCP/IP.
Walaupun alamat IP disimpan sebagai angka biner, mereka biasanya ditampilkan agar memudahkan manusia menggunakan notasi, seperti 208.77.188.166 (untuk IPv4), dan 2001: db8: 0:1234:0:567:1:1 (untuk IPv6).
Internet Protocol juga memiliki tugas routing paket data antara jaringan, alamat IP dan menentukan lokasi dari node sumber dan node tujuan dalam topologi dari sistem routing. Untuk tujuan ini, beberapa bit pada alamat IP yang digunakan untuk menunjuk sebuah subnetwork. Jumlah bit ini ditunjukkan dalam notasi CIDR, yang ditambahkan ke alamat IP, misalnya, 208.77.188.166/24.
Sistem pengalamatan IP ini terbagi menjadi dua, yakni:
* IP versi 4 (IPv4)
* IP versi 6 (IPv6)
Pengiriman data dalam jaringan TCP/IP berdasarkan IP address komputer pengirim dan komputer penerima. IP address memiliki dua bagian, yaitu alamat jaringan (network address) dan alamat komputer lokal (host address) dalam sebuah jaringan.
Alamat jaringan digunakan oleh router untuk mencari jaringan tempat sebuah komputer lokal berada, semantara alamat komputer lokal digunakan untuk mengenali sebuah komputer pada jaringan lokal. 1. Alamat IP versi 4
Alamat IP versi 4 (sering disebut dengan Alamat IPv4) adalah sebuah jenis pengalamatan jaringan yang digunakan di dalam protokol jaringan TCP/IP yang menggunakan protokol IP versi 4. Panjang totalnya adalah 32-bit, dan secara teoritis dapat mengalamati hingga 4 miliar host komputer atau lebih tepatnya 4.294.967.296 host di seluruh dunia, jumlah host tersebut didapatkan dari 256 (didapatkan dari 8 bit) dipangkat 4(karena terdapat 4 oktet) sehingga nilai maksimal dari alamt IP versi 4 tersebut adalah 255.255.255.255 dimana nilai dihitung dari nol sehingga nilai nilai host yang dapat ditampung adalah 256x256x256x256=4.294.967.296 host. sehingga bila host yang ada diseluruh dunia melebihi kuota tersebut maka dibuatlah IP versi 6 atau IPv6.
Contoh alamat IP versi 4 adalah 192.168.0.3.
Alamat IPv4 terbagi menjadi beberapa jenis, yakni sebagai berikut: 1. Alamat Unicast, merupakan alamat IPv4 yang ditentukan untuk sebuah antarmuka jaringan yang dihubungkan ke sebuah internetwork IP. Alamat Unicast digunakan dalam komunikasi point-to-point atau one-to-one. Alamat unicast menggunakan kelas A, B, dan C dari kelas-kelas alamat IP yang telah disebutkan sebelumnya.
Dalam RFC 791 alamat Unicast IP versi 4 dibagi ke dalam beberapa kelas, dilihat dari oktet pertamanya, seperti terlihat pada tabel. Sebenarnya yang menjadi pembeda kelas IP versi 4 adalah pola biner yang terdapat dalam oktet pertama (utamanya adalah bit-bit awal/high-order bit), tapi untuk lebih mudah mengingatnya, akan lebih cepat diingat dengan menggunakan representasi desimal.
Kelas Alamat IP Oktet pertamaTemplate:Br(desimal) Oktet pertamaTemplate:Br(biner) Digunakan oleh
Kelas A 1–126 0xxx xxxx Alamat unicast untuk jaringan skala besar
Kelas B 128–191 1xxx xxxx Alamat unicast untuk jaringan skala menengah hingga skala besar
Kelas C 192–223 110x xxxx Alamat unicast untuk jaringan skala kecil
Kelas D 224–239 1110 xxxx Alamat multicast (bukan alamat unicast)
Kelas E 240–255 1111 xxxx Direservasikan;umumnya digunakan sebagai alamat percobaan (eksperimen); (bukan alamat unicast)
Kelas A
Alamat-alamat unicast kelas A diberikan untuk jaringan skala besar. Nomor urut bit tertinggi di dalam alamat IP kelas A selalu diset dengan nilai 0 (nol). Tujuh bit berikutnya—untuk melengkapi oktet pertama—akan membuat sebuah network identifier. 24 bit sisanya (atau tiga oktet terakhir) merepresentasikan host identifier. Ini mengizinkan kelas A memiliki hingga 126 jaringan, dan 16,777,214 host tiap jaringannya. Alamat dengan oktet awal 127 tidak diizinkan, karena digunakan untuk mekanisme Interprocess Communication (IPC) di dalam mesin yang bersangkutan.
Kelas B
Alamat-alamat unicast kelas B dikhususkan untuk jaringan skala menengah hingga skala besar. Dua bit pertama di dalam oktet pertama alamat IP kelas B selalu diset ke bilangan biner 10. 14 bit berikutnya (untuk melengkapi dua oktet pertama), akan membuat sebuah network identifier. 16 bit sisanya (dua oktet terakhir) merepresentasikan host identifier. Kelas B dapat memiliki 16,384 network, dan 65,534 host untuk setiap network-nya.
Kelas C
Alamat IP unicast kelas C digunakan untuk jaringan berskala kecil. Tiga bit pertama di dalam oktet pertama alamat kelas C selalu diset ke nilai biner 110. 21 bit selanjutnya (untuk melengkapi tiga oktet pertama) akan membentuk sebuah network identifier. 8 bit sisanya (sebagai oktet terakhir) akan merepresentasikan host identifier. Ini memungkinkan pembuatan total 2,097,152 buah network, dan 254 host untuk setiap network-nya.
Kelas D
Alamat IP kelas D disediakan hanya untuk alamat-alamat IP multicast, sehingga berbeda dengan tiga kelas di atas. Empat bit pertama di dalam IP kelas D selalu diset ke bilangan biner 1110. 28 bit sisanya digunakan sebagai alamat yang dapat digunakan untuk mengenali host. Untuk lebih jelas mengenal alamat ini, lihat pada bagian Alamat Multicast IPv4.
Kelas E
Alamat IP kelas E disediakan sebagai alamat yang bersifat “eksperimental” atau percobaan dan dicadangkan untuk digunakan pada masa depan. Empat bit pertama selalu diset kepada bilangan biner 1111. 28 bit sisanya digunakan sebagai alamat yang dapat digunakan untuk mengenali host.
Kelas Alamat Nilai oktet pertama Bagian untuk Network Identifier Bagian untuk Host Identifier Jumlah jaringan maksimum Jumlah host dalam satu jaringan maksimum
Kelas A 1–126 W X.Y.Z 126 16,777,214
Kelas B 128–191 W.X Y.Z 16,384 65,534
Kelas C 192–223 W.X.Y Z 2,097,152 254
Kelas D 224-239 Multicast IP Address Multicast IP Address Multicast IP Address Multicast IP Address
Kelas E 240-255 Dicadangkan; eksperimen Dicadangkan; eksperimen Dicadangkan; eksperimen Dicadangkan; eksperimen
Catatan: Penggunaan kelas alamat IP sekarang tidak relevan lagi, mengingat sekarang alamat IP sudah tidak menggunakan kelas alamat lagi. Pengemban otoritas Internet telah melihat dengan jelas bahwa alamat yang dibagi ke dalam kelas-kelas seperti di atas sudah tidak mencukupi kebutuhan yang ada saat ini, di saat penggunaan Internet yang semakin meluas. Alamat IPv6 yang baru sekarang tidak menggunakan kelas-kelas seperti alamat IPv4. Alamat yang dibuat tanpa mempedulikan kelas disebut juga dengan classless address. 2.Alamat Broadcast, merupakan alamat IPv4 yang didesain agar diproses oleh setiap node IP dalam segmen jaringan yang sama. Alamat broadcast digunakan dalam komunikasi one-to-everyone.
Alamat broadcast IP versi 4 digunakan untuk menyampaikan paket-paket data “satu-untuk-semua”. Jika sebuah host pengirim yang hendak mengirimkan paket data dengan tujuan alamat broadcast, maka semua node yang terdapat di dalam segmen jaringan tersebut akan menerima paket tersebut dan memprosesnya. Berbeda dengan alamat IP unicast atau alamat IP multicast, alamat IP broadcast hanya dapat digunakan sebagai alamat tujuan saja, sehingga tidak dapat digunakan sebagai alamat sumber.
Ada empat buah jenis alamat IP broadcast, yakni network broadcast, subnet broadcast, all-subnets-directed broadcast, dan Limited Broadcast. Untuk setiap jenis alamat broadcast tersebut, paket IP broadcast akan dialamatkan kepada lapisan antarmuka jaringan dengan menggunakan alamat broadcast yang dimiliki oleh teknologi antarmuka jaringan yang digunakan. Sebagai contoh, untuk jaringan Ethernet dan Token Ring, semua paket broadcast IP akan dikirimkan ke alamat broadcast Ethernet dan Token Ring, yakni 0xFF-FF-FF-FF-FF-FF.
a.Network Broadcast
Alamat network broadcast IPv4 adalah alamat yang dibentuk dengan cara mengeset semua bit host menjadi 1 dalam sebuah alamat yang menggunakan kelas (classful). Contohnya adalah, dalam NetID 131.107.0.0/16, alamat broadcast-nya adalah 131.107.255.255. Alamat network broadcast digunakan untuk mengirimkan sebuah paket untuk semua host yang terdapat di dalam sebuah jaringan yang berbasis kelas. Router tidak dapat meneruskan paket-paket yang ditujukan dengan alamat network broadcast.
b.Subnet broadcast
Alamat subnet broadcast adalah alamat yang dibentuk dengan cara mengeset semua bit host menjadi 1 dalam sebuah alamat yang tidak menggunakan kelas (classless). Sebagai contoh, dalam NetID 131.107.26.0/24, alamat broadcast-nya adalah 131.107.26.255. Alamat subnet broadcast digunakan untuk mengirimkan paket ke semua host dalam sebuah jaringan yang telah dibagi dengan cara subnetting, atau supernetting. Router tidak dapat meneruskan paket-paket yang ditujukan dengan alamat subnet broadcast.
Alamat subnet broadcast tidak terdapat di dalam sebuah jaringan yang menggunakan kelas alamat IP, sementara itu, alamat network broadcast tidak terdapat di dalam sebuah jaringan yang tidak menggunakan kelas alamat IP.
c.All-subnets-directed broadcast
Alamat IP ini adalah alamat broadcast yang dibentuk dengan mengeset semua bit-bit network identifier yang asli yang berbasis kelas menjadi 1 untuk sebuah jaringan dengan alamat tak berkelas (classless). Sebuah paket jaringan yang dialamatkan ke alamat ini akan disampaikan ke semua host dalam semua subnet yang dibentuk dari network identifer yang berbasis kelas yang asli. Contoh untuk alamat ini adalah untuk sebuah network identifier 131.107.26.0/24, alamat all-subnets-directed broadcast untuknya adalah 131.107.255.255. Dengan kata lain, alamat ini adalah alamat jaringan broadcast dari network identifier alamat berbasis kelas yang asli. Dalam contoh di atas, alamat 131.107.26.0/24 yang merupakan alamat kelas B, yang secara default memiliki network identifer 16, maka alamatnya adalah 131.107.255.255.
Semua host dari sebuah jaringan dengan alamat tidak berkelas akan menengarkan dan memproses paket-paket yang dialamatkan ke alamat ini. RFC 922 mengharuskan router IP untuk meneruskan paket yang di-broadcast ke alamat ini ke semua subnet dalam jaringan berkelas yang asli. Meskipun demikian, hal ini belum banyak diimplementasikan.
Dengan banyaknya alamat network identifier yang tidak berkelas, maka alamat ini pun tidak relevan lagi dengan perkembangan jaringan. Menurut RFC 1812, penggunaan alamat jenis ini telah ditinggalkan.
d.Limited broadcast
Alamat ini adalah alamat yang dibentuk dengan mengeset semua 32 bit alamat IP versi 4 menjadi 1 (11111111111111111111111111111111 atau 255.255.255.255). Alamat ini digunakan ketika sebuah node IP harus melakukan penyampaian data secara one-to-everyone di dalam sebuah jaringan lokal tetapi ia belum mengetahui network identifier-nya. Contoh penggunaanya adalah ketika proses konfigurasi alamat secara otomatis dengan menggunakan Boot Protocol (BOOTP) atau Dynamic Host Configuration Protocol (DHCP). Sebagai contoh, dengan DHCP, sebuah klien DHCP harus menggunakan alamat ini untuk semua lalu lintas yang dikirimkan hingga server DHCP memberikan sewaan alamat IP kepadanya.
Semua host, yang berbasis kelas atau tanpa kelas akan mendengarkan dan memproses paket jaringan yang dialamatkan ke alamat ini. Meskipun kelihatannya dengan menggunakan alamat ini, paket jaringan akan dikirimkan ke semua node di dalam semua jaringan, ternyata hal ini hanya terjadi di dalam jaringan lokal saja, dan tidak akan pernah diteruskan oleh router IP, mengingat paket data dibatasi saja hanya dalam segmen jaringan lokal saja. Karenanya, alamat ini disebut sebagai limited broadcast. 3.Alamat Multicast, merupakan alamat IPv4 yang didesain agar diproses oleh satu atau beberapa node dalam segmen jaringan yang sama atau berbeda. Alamat multicast digunakan dalam komunikasi one-to-many.
Alamat IP Multicast (multicast IP address) adalah alamat yang digunakan untuk menyampaikan satu paket kepada banyak penerima. Dalam sebuah intranet yang memiliki alamat multicast IPv4, sebuah paket yang ditujukan ke sebuah alamat multicast akan diteruskan oleh router ke subjaringan di mana terdapat host-host yang sedang berada dalam kondisi “listening” terhadap lalu lintas jaringan yang dikirimkan ke alamat multicast tersebut. Dengan cara ini, alamat multicast pun menjadi cara yang efisien untuk mengirimkan paket data dari satu sumber ke beberapa tujuan untuk beberapa jenis komunikasi. Alamat multicast didefinisikan dalam RFC 1112.
Alamat-alamat multicast IPv4 didefinisikan dalam ruang alamat kelas D, yakni 224.0.0.0/4, yang berkisar dari 224.0.0.0 hingga 239.255.255.255. Prefiks alamat 224.0.0.0/24 (dari alamat 224.0.0.0 hingga 224.0.0.255) tidak dapat digunakan karena dicadangkan untuk digunakan oleh lalu lintas multicast dalam subnet lokal.
Daftar alamat multicast yang ditetapkan oleh IANA dapat dilihat pada situs IANA Alamat IP lainnya
Jika ada sebuah intranet tidak yang terkoneksi ke internet, semua alamat IP dapat digunakan. Jika koneksi dilakukan secara langsung (dengan menggunakan teknik routing) atau secara tidak langsung (dengan menggunakan proxy server), maka ada dua jenis alamat yang dapat digunakan di dalam internet, yaitu public address (alamat publik) dan private address (alamat pribadi). 1.Alamat publik
alamat publik adalah alamat-alamat yang telah ditetapkan oleh InterNIC dan berisi beberapa buah network identifier yang telah dijamin unik (artinya, tidak ada dua host yang menggunakan alamat yang sama) jika intranet tersebut telah terhubung ke Internet.
Ketika beberapa alamat publik telah ditetapkan, maka beberapa rute dapat diprogram ke dalam sebuah router sehingga lalu lintas data yang menuju alamat publik tersebut dapat mencapai lokasinya. Di internet, lalu lintas ke sebuah alamat publik tujuan dapat dicapai, selama masih terkoneksi dengan internet. 2.Alamat ilegal
Intranet-intranet pribadi yang tidak memiliki kemauan untuk mengoneksikan intranetnya ke internet dapat memilih alamat apapun yang mereka mau, meskipun menggunakan alamat publik yang telah ditetapkan oleh InterNIC. Jika sebuah organisasi selanjutnya memutuskan untuk menghubungkan intranetnya ke internet, skema alamat yang digunakannya mungkin dapat mengandung alamat-alamat yang mungkin telah ditetapkan oleh InterNIC atau organisasi lainnya. Alamat-alamat tersebut dapat menjadi konflik antara satu dan lainnya, sehingga disebut juga dengan illegal address, yang tidak dapat dihubungi oleh host lainnya. 3.Alamat Privat
Setiap node IP membutuhkan sebuah alamat IP yang secara global unik terhadap internetwork IP. Pada kasus internet, setiap node di dalam sebuah jaringan yang terhubung ke internet akan membutuhkan sebuah alamat yang unik secara global terhadap internet. Karena perkembangan internet yang sangat amat pesat, organisasi-organisasi yang menghubungkan intranet miliknya ke internet membutuhkan sebuah alamat publik untuk setiap node di dalam intranet miliknya tersebut. Tentu saja, hal ini akan membutuhkan sebuah alamat publik yang unik secara global.
Ketika menganalisis kebutuhan pengalamatan yang dibutuhkan oleh sebuah organisasi, para desainer internet memiliki pemikiran yaitu bagi kebanyakan organisasi, kebanyakan host di dalam intranet organisasi tersebut tidak harus terhubung secara langsung ke internet. Host-host yang membutuhkan sekumpulan layanan internet, seperti halnya akses terhadap web atau e-mail, biasanya mengakses layanan internet tersebut melalui gateway yang berjalan di atas lapisan aplikasi seperti proxy server atau e-mail server. Hasilnya, kebanyakan organisasi hanya membutuhkan alamat publik dalam jumlah sedikit saja yang nantinya digunakan oleh node-node tersebut (hanya untuk proxy, router, firewall, atau translator) yang terhubung secara langsung ke internet.
Untuk host-host di dalam sebuah organisasi yang tidak membutuhkan akses langsung ke internet, alamat-alamat IP yang bukan duplikat dari alamat publik yang telah ditetapkan mutlak dibutuhkan. Untuk mengatasi masalah pengalamatan ini, para desainer internet mereservasikan sebagian ruangan alamat IP dan menyebut bagian tersebut sebagai ruangan alamat pribadi. Sebuah alamat IP yang berada di dalam ruangan alamat pribadi tidak akan digunakan sebagai sebuah alamat publik. Alamat IP yang berada di dalam ruangan alamat pribadi dikenal juga dengan alamat pribadi. Karena di antara ruangan alamat publik dan ruangan alamat pribadi tidak saling melakukan overlapping, maka alamat pribadi tidak akan menduplikasi alamat publik, dan tidak pula sebaliknya.
Ruangan alamat pribadi yang ditentukan di dalam RFC 1918 didefinisikan di dalam tiga blok alamat berikut:
* 10.0.0.0/8
* 172.16.0.0/12
* 192.168.0.0/16 a.10.0.0.0/8
Jaringan pribadi (private network) 10.0.0.0/8 merupakan sebuah network identifier kelas A yang mengizinkan alamat IP yang valid dari 10.0.0.1 hingga 10.255.255.254. Private network 10.0.0.0/8 memiliki 24 bit host yang dapat digunakan untuk skema subnetting di dalam sebuah organisasi privat. b.172.16.0.0/12
Jaringan pribadi 172.16.0.0/12 dapat diinterpretasikan sebagai sebuah block dari 16 network identifier kelas B atau sebagai sebuah ruangan alamat yang memiliki 20 bit yang dapat ditetapkan sebagai host identifier, yang dapat digunakan dengan menggunakan skema subnetting di dalam sebuah organisasi privat. Alamat jaringan privat 17.16.0.0/12 mengizinkan alamat-alamat IP yang valid dari 172.16.0.1 hingga 172.31.255.254. c.192.168.0.0/16
Jaringan pribadi 192.168.0.0/16 dapat diinterpretasikan sebagai sebuah block dari 256 network identifier kelas C atau sebagai sebuah ruangan alamat yang memiliki 16 bit yang dapat ditetapkan sebagai host identifier yang dapat digunakan dengan menggunakan skema subnetting apapun di dalam sebuah organisasi privat. Alamat private network 192.168.0.0/16 dapat mendukung alamat-alamat IP yang valid dari 192.168.0.1 hingga 192.168.255.254. d.169.254.0.0/16
Alamat jaringan ini dapat digunakan sebagai alamat privat karena memang IANA mengalokasikan untuk tidak menggunakannya. Alamat IP yang mungkin dalam ruang alamat ini adalah 169.254.0.1 hingga 169.254.255.254, dengan alamat subnet mask 255.255.0.0. Alamat ini digunakan sebagai alamat IP privat otomatis (dalam Windows, disebut dengan Automatic Private Internet Protocol Addressing (APIPA)).
Hasil dari penggunaan alamat-alamat privat ini oleh banyak organisasi adalah menghindari kehabisan dari alamat publik, mengingat pertumbuhan internet yang sangat pesat.
Karena alamat-alamat IP di dalam ruangan alamat pribadi tidak akan ditetapkan oleh Internet Network Information Center (InterNIC) (atau badan lainnya yang memiliki otoritas) sebagai alamat publik, maka tidak akan pernah ada rute yang menuju ke alamat-alamat pribadi tersebut di dalam router internet. Kompensasinya, alamat pribadi tidak dapat dijangkau dari internet. Oleh karena itu, semua lalu lintas dari sebuah host yang menggunakan sebuah alamat pribadi harus mengirim request tersebut ke sebuah gateway (seperti halnya proxy server), yang memiliki sebuah alamat publik yang valid, atau memiliki alamat pribadi yang telah ditranslasikan ke dalam sebuah alamat IP publik yang valid dengan menggunakan Network Address Translator (NAT) sebelum dikirimkan ke internet. Format Paket IPv4
Paket-paket data dalam protokol IP dikirimkan dalam bentuk datagram. Sebuah datagram IP terdiri atas header IP dan muatan IP (payload). Header IP menyediakan dukungan untuk memetakan jaringan (routing), identifikasi muatan IP, ukuran header IP dan datagram IP, dukungan fragmentasi, dan juga IP Options. Sedangkan payload IP berisi informasi yang dikirimkan. Payload IP memiliki ukuran bervariasi, berkisar dari 8 byte hingga 65515 byte. Sebelum dikirimkan di dalam saluran jaringan, datagram IP akan “dibungkus” (encapsulation) dengan header protokol lapisan antarmuka jaringan dan trailer-nya, untuk membuat sebuah frame jaringan. Setiap datagram terdiri dari beberapa field yang memiliki fungsi tersendiri dan memiliki informasi yang berbeda – beda. Pada gambar di bawah ini . dapat dilihat struktur dari paket IPv4 Header IP terdiri atas beberapa field sebagai berikut:
a. Version. Digunakan untuk mengindikasikan versi dari header IP yang digunakan
b. Internet Header Length. Digunakan untuk mengindikasikan ukuran header IP.
c. Type of Service. Field ini digunakan untuk menentukan kualitas transmisi dari sebuah datagram IP.
d. Total Length. Merupakan panjang total dari datagram IP, yang mencakup header IP dan muatannya.
e. Identification. Digunakan untuk mengidentifikasikan sebuah paket IP tertentu yang akan difragmentasi..
f. Flags. Berisi dua buah flag yang berisi apakah sebuah datagram IP mengalami fragmentasi atau tidak.
* · Bit 0 = reserved, diisi 0.
* · Bit 1 = bila 0 bisa difragmentasi, bila 1 tidak dapat difragmentasi.
* · Bit 1 = bila 0 fragmentasi berakhir, bila 1 ada fragmentasi lagi.
g. Fragment Offset. Digunakan untuk mengidentifikasikan offset di mana fragmen yang bersangkutan dimulai, dihitung dari permulaan muatan IP yang belum dipecah.
h. Time to Live. Digunakan untuk mengidentifikasikan berapa banyak saluran jaringan di mana sebuah datagram IP dapat berjalan-jalan sebelum sebuah router mengabaikan datagram tersebut.
i. Protocol. Digunakan untuk mengidentifikasikan jenis protokol lapisan yang lebih tinggi yang dikandung oleh muatan IP.
J.Header Checksum. Field ini berguna hanya untuk melakukan pengecekan
integritas terhadap header IP.
k. Source IP Address. Mengandung alamat IP dari sumber host yang mengirimkan datagram IP tersebut.
l. Destination IP Address. Mengandung alamat IP tujuan ke mana datagram IP tersebut akan disampaikan, Alamat IP versi 6
Berbeda dengan IPv4 yang hanya memiliki panjang 32-bit (jumlah total alamat yang dapat dicapainya mencapai 4,294,967,296 alamat), IPv6 memiliki panjang 128-bit. IPv4, meskipun total alamatnya mencapai 4 miliar, pada kenyataannya tidak sampai 4 miliar alamat, karena ada beberapa limitasi, sehingga implementasinya saat ini hanya mencapai beberapa ratus juta saja. IPv6, yang memiliki panjang 128-bit, memiliki total alamat yang mungkin hingga 2128=3,4 x 1038 alamat. Total alamat yang sangat besar ini bertujuan untuk menyediakan ruang alamat yang tidak akan habis (hingga beberapa masa ke depan), dan membentuk infrastruktur routing yang disusun secara hierarkis, sehingga mengurangi kompleksitas proses routing dan tabel routing.
Sama seperti halnya IPv4, IPv6 juga mengizinkan adanya DHCP Server sebagai pengatur alamat otomatis. Jika dalam IPv4 terdapat dynamic address dan static address, maka dalam IPv6, konfigurasi alamat dengan menggunakan DHCP Server dinamakan dengan stateful address configuration, sementara jika konfigurasi alamat IPv6 tanpa DHCP Server dinamakan dengan stateless address configuration.
Seperti halnya IPv4 yang menggunakan bit-bit pada tingkat tinggi (high-order bit) sebagai alamat jaringan sementara bit-bit pada tingkat rendah (low-order bit) sebagai alamat host, dalam IPv6 juga terjadi hal serupa. Dalam IPv6, bit-bit pada tingkat tinggi akan digunakan sebagai tanda pengenal jenis alamat IPv6, yang disebut dengan Format Prefix (FP). Dalam IPv6, tidak ada subnet mask, yang ada hanyalah Format Prefix.
Pengalamatan IPv6 didefinisikan dalam RFC 2373. Format Alamat
Dalam IPv6, alamat 128-bit akan dibagi ke dalam 8 blok berukuran 16-bit, yang dapat dikonversikan ke dalam bilangan heksadesimal berukuran 4-digit. Setiap blok bilangan heksadesimal tersebut akan dipisahkan dengan tanda titik dua (:). Karenanya, format notasi yang digunakan oleh IPv6 juga sering disebut dengan colon-hexadecimal format, berbeda dengan IPv4 yang menggunakan dotted-decimal format.
Berikut ini adalah contoh alamat IPv6 dalam bentuk bilangan biner:
00100001110110100000000011010011000000000000000000101111001110110000001010101010000000001111111111111110001010001001110001011010
Untuk menerjemahkannya ke dalam bentuk notasi colon-hexadecimal format, angka-angka biner di atas harus dibagi ke dalam 8 buah blok berukuran 16-bit:
0010000111011010 0000000011010011 0000000000000000 0010111100111011 0000001010101010 0000000011111111 1111111000101000 1001110001011010
Lalu, setiap blok berukuran 16-bit tersebut harus dikonversikan ke dalam bilangan heksadesimal dan setiap bilangan heksadesimal tersebut dipisahkan dengan menggunakan tanda titik dua. Hasil konversinya adalah sebagai berikut:
21DA:00D3:0000:2F3B:02AA:00FF:FE28:9C5A Penyederhanaan bentuk alamat
Alamat di atas juga dapat disederhanakan lagi dengan membuang angka 0 pada awal setiap blok yang berukuran 16-bit di atas, dengan menyisakan satu digit terakhir. Dengan membuang angka 0, alamat di atas disederhanakan menjadi:
21DA:D3:0:2F3B:2AA:FF:FE28:9C5A
Konvensi pengalamatan IPv6 juga mengizinkan penyederhanaan alamat lebih jauh lagi, yakni dengan membuang banyak karakter 0, pada sebuah alamat yang banyak angka 0-nya. Jika sebuah alamat IPv6 yang direpresentasikan dalam notasi colon-hexadecimal format mengandung beberapa blok 16-bit dengan angka 0, maka alamat tersebut dapat disederhanakan dengan menggunakan tanda dua buah titik dua (::). Untuk menghindari kebingungan, penyederhanaan alamat IPv6 dengan cara ini sebaiknya hanya digunakan sekali saja di dalam satu alamat, karena kemungkinan nantinya pengguna tidak dapat menentukan berapa banyak bit 0 yang direpresentasikan oleh setiap tanda dua titik dua (::) yang terdapat dalam alamat tersebut. Tabel berikut mengilustrasikan cara penggunaan hal ini.
Alamat asli Alamat asli yang disederhanakan Alamat setelah dikompres
FE80:0000:0000:0000:02AA:00FF:FE9A:4CA2 FE80:0:0:0:2AA:FF:FE9A:4CA2 FE80::2AA:FF:FE9A:4CA2
FF02:0000:0000:0000:0000:0000:0000:0002 FF02:0:0:0:0:0:0:2 FF02::2
Untuk menentukan berapa banyak bit bernilai 0 yang dibuang (dan digantikan dengan tanda dua titik dua) dalam sebuah alamat IPv6, dapat dilakukan dengan menghitung berapa banyak blok yang tersedia dalam alamat tersebut, yang kemudian dikurangkan dengan angka 8, dan angka tersebut dikalikan dengan 16. Sebagai contoh, alamat FF02::2 hanya mengandung dua blok alamat (blok FF02 dan blok 2). Maka, jumlah bit yang dibuang adalah (8-2) x 16 = 96 buah bit. Format Prefix
Dalam IPv4, sebuah alamat dalam notasi dotted-decimal format dapat direpresentasikan dengan menggunakan angka prefiks yang merujuk kepada subnet mask. IPv6 juga memiliki angka prefiks, tapi tidak didugnakan untuk merujuk kepada subnet mask, karena memang IPv6 tidak mendukung subnet mask.
Prefiks adalah sebuah bagian dari alamat IP, di mana bit-bit memiliki nilai-nilai yang tetap atau bit-bit tersebut merupakan bagian dari sebuah rute atau subnet identifier. Prefiks dalam IPv6 direpesentasikan dengan cara yang sama seperti halnya prefiks alamat IPv4, yaitu [alamat]/[angka panjang prefiks]. Panjang prefiks mementukan jumlah bit terbesar paling kiri yang membuat prefiks subnet. Sebagai contoh, prefiks sebuah alamat IPv6 dapat direpresentasikan sebagai berikut:
3FFE:2900:D005:F28B::/64
Pada contoh di atas, 64 bit pertama dari alamat tersebut dianggap sebagai prefiks alamat, sementara 64 bit sisanya dianggap sebagai interface ID. Jenis-jenis Alamat IPv6
IPv6 mendukung beberapa jenis format prefix, yakni sebagai berikut:
* Alamat Unicast, yang menyediakan komunikasi secara point-to-point, secara langsung antara dua host dalam sebuah jaringan.
* Alamat Multicast, yang menyediakan metode untuk mengirimkan sebuah paket data ke banyak host yang berada dalam group yang sama. Alamat ini digunakan dalam komunikasi one-to-many.
* Alamat Anycast, yang menyediakan metode penyampaian paket data kepada anggota terdekat dari sebuah group. Alamat ini digunakan dalam komunikasi one-to-one-of-many. Alamat ini juga digunakan hanya sebagai alamat tujuan (destination address) dan diberikan hanya kepada router, bukan kepada host-host biasa.
Jika dilihat dari cakupan alamatnya, alamat unicast dan anycast terbagi menjadi alamat-alamat berikut:
* Link-Local, merupakan sebuah jenis alamat yang mengizinkan sebuah komputer agar dapat berkomunikasi dengan komputer lainnya dalam satu subnet.
* Site-Local, merupakan sebuah jenis alamat yang mengizinkan sebuah komputer agar dapat berkomunikasi dengan komputer lainnya dalam sebuah intranet.
* Global Address, merupakan sebuah jenis alamat yang mengizinkan sebuah komputer agar dapat berkomunikasi dengan komputer lainnya dalam Internet IPv6.
Sementara itu, cakupan alamat multicast dimasukkan ke dalam struktur alamat. Unicast Address
Alamat unicast IPv6 dapat diimplementasikan dalam berbagai jenis alamat, yakni:
* Alamat unicast global
* Alamat unicast site-local
* Alamat unicast link-local
* Alamat unicast yang belum ditentukan (unicast unspecified address)
* Alamat unicast loopback
* Alamat Unicast 6to4
* Alamat Unicast ISATAP Unicast global addresses
Alamat unicast global IPv6 mirip dengan alamat publik dalam alamat IPv4. Dikenal juga sebagai Aggregatable Global Unicast Address. Seperti halnya alamat publik IPv4 yang dapat secara global dirujuk oleh host-host di Internet dengan menggunakan proses routing, alamat ini juga mengimplementasikan hal serupa. Struktur alamat IPv6 unicast global terbagi menjadi topologi tiga level (Public, Site, dan Node).
Field Panjang Keterangan
001 3 bit Berfungsi sebagai tanda pengenal alamat, bahwa alamat ini adalah sebuah alamat IPv6 Unicast Global.
Top Level Aggregation Identifier (TLA ID) 13 bit Berfungsi sebagai level tertinggi dalam hierarki routing. TLA ID diatur oleh Internet Assigned Name Authority (IANA), yang mengalokasikannya ke dalam daftar Internet registry, yang kemudian mengolasikan sebuah TLA ID ke sebuah ISP global.
Res 8 bit Direservasikan untuk penggunaan pada masa yang akan datang (mungkin untuk memperluas TLA ID atau NLA ID).
Next Level Aggregation Identifier (NLA ID) 24 bit Berfungsi sebagai tanda pengenal milik situs (site) kustomer tertentu.
Site Level Aggregation Identifier (SLA ID) 16 bit Mengizinkan hingga 65536 (216) subnet dalam sebuah situs individu. SLA ID ditetapkan di dalam sebuah site. ISP tidak dapat mengubah bagian alamat ini.
Interface ID 64 bit Berfungsi sebagai alamat dari sebuah node dalam subnet yang spesifik (yang ditentukan oleh SLA ID). Unicast site-local addresses
Alamat unicast site-local IPv6 mirip dengan alamat privat dalam IPv4. Ruang lingkup dari sebuah alamat terdapat pada internetwork dalam sebuah site milik sebuah organisasi. Penggunaan alamat unicast global dan unicast site-local dalam sebuah jaringan adalah mungkin. Prefiks yang digunakan oleh alamat ini adalah FEC0::/48.
Field Panjang Keterangan
111111101100000000000000000000000000000000000000 48 bit Nilai ketetapan alamat unicast site-local
Subnet Identifier 16 bit Mengizinkan hingga 65536 (216) subnet dalam sebuah struktur subnet datar. Administrator juga dapat membagi bit-bit yang yang memiliki nilai tinggi (high-order bit) untuk membuat sebuah infrastruktur routing hierarkis.
Interface Identifier 64 bit Berfungsi sebagai alamat dari sebuah node dalam subnet yang spesifik. Unicast link-local address
Alamat unicast link-local adalah alamat yang digunakan oleh host-host dalam subnet yang sama. Alamat ini mirip dengan konfigurasi APIPA (Automatic Private Internet Protocol Addressing) dalam sistem operasi Microsoft Windows XP ke atas. host-host yang berada di dalam subnet yang sama akan menggunakan alamat-alamat ini secara otomatis agar dapat berkomunikasi. Alamat ini juga memiliki fungsi resolusi alamat, yang disebut dengan Neighbor Discovery. Prefiks alamat yang digunakan oleh jenis alamat ini adalah FE80::/64.
Field Panjang Keterangan
1111111010000000000000000000000000000000000000000000000000000000 64 bit Berfungsi sebagai tanda pengenal alamat unicast link-local.
Interface ID 64 bit Berfungsi sebagai alamat dari sebuah node dalam subnet yang spesifik. Unicast unspecified address
Alamat Unicast yang belum ditentukan adalah alamat yang belum ditentukan oleh seorang administrator atau tidak menemukan sebuah DHCP Server untuk meminta alamat. Alamat ini sama dengan alamat IPv4 yang belum ditentukan, yakni 0.0.0.0. Nilai alamat ini dalam IPv6 adalah 0:0:0:0:0:0:0:0 atau dapat disingkat menjadi dua titik dua (::). Unicast Loopback Address
Alamat unicast loopback adalah sebuah alamat yang digunakan untuk mekanisme interprocess communication (IPC) dalam sebuah host. Dalam IPv4, alamat yang ditetapkan adalah 127.0.0.1, sementara dalam IPv6 adalah 0:0:0:0:0:0:0:1, atau ::1. Unicast 6to4 Address
Alamat unicast 6to4 adalah alamat yang digunakan oleh dua host IPv4 dan IPv6 dalam Internet IPv4 agar dapat saling berkomunikasi. Alamat ini sering digunakan sebagai pengganti alamat publik IPv4. Alamat ini aslinya menggunakan prefiks alamat 2002::/16, dengan tambahan 32 bit dari alamat publik IPv4 untuk membuat sebuah prefiks dengan panjang 48-bit, dengan format 2002:WWXX:YYZZ::/48, di mana WWXX dan YYZZ adalah representasi dalam notasi colon-decimal format dari notasi dotted-decimal format w.x.y.z dari alamat publik IPv4. Sebagai contoh alamat 157.60.91.123 diterjemahkan menjadi 2002:9D3C:5B7B::/48.
Meskipun demikian, alamat ini sering ditulis dalam format IPv6 Unicast global address, 2002:WWXX:YYZZ:SLA ID:Interface ID. Unicast ISATAP Address
Alamat Unicast ISATAP adalah sebuah alamat yang digunakan oleh dua host IPv4 dan IPv6 dalam sebuah Intranet IPv4 agar dapat saling berkomunikasi. Alamat ini menggabungkan prefiks alamat unicast link-local, alamat unicast site-local atau alamat unicast global (yang dapat berupa prefiks alamat 6to4) yang berukuran 64-bit dengan 32-bit ISATAP Identifier (0000:5EFE), lalu diikuti dengan 32-bit alamat IPv4 yang dimiliki oleh interface atau sebuah host. Prefiks yang digunakan dalam alamat ini dinamakan dengan subnet prefix. Meski alamat 6to4 hanya dapat menangani alamat IPv4 publik saja, alamat ISATAP dapat menangani alamat pribadi IPv4 dan alamat publik IPv4. Multicast Address
Alamat multicast IPv6 sama seperti halnya alamat multicast pada IPv4. Paket-paket yang ditujukan ke sebuah alamat multicast akan disampaikan terhadap semua interface yang dikenali oleh alamat tersebut. Prefiks alamat yang digunakan oleh alamat multicast IPv6 adalah FF00::/8.
Field Panjang Keterangan
1111 1111 8 bit Tanda pengenal bahwa alamat ini adalah alamat multicast.
Flags 4 bit Berfungsi sebagai tanda pengenal apakah alamat ini adalah alamat transient atau bukan. Jika nilainya 0, maka alamat ini bukan alamat transient, dan alamat ini merujuk kepada alamat multicast yang ditetapkan secara permanen. Jika nilainya 1, maka alamat ini adalah alamat transient.
Scope 4 bit Berfungsi untuk mengindikasikan cakupan lalu lintas multicast, seperti halnya interface-local, link-local, site-local, organization-local atau global.
Group ID 112 bit Berfungsi sebagai tanda pengenal group multicast Anycast Address
Alamat Anycast dalam IPv6 mirip dengan alamat anycast dalam IPv4, tapi diimplementasikan dengan cara yang lebih efisien dibandingkan dengan IPv4. Umumnya, alamat anycast digunakan oleh Internet Service Provider (ISP) yang memiliki banyak klien. Meskipun alamat anycast menggunakan ruang alamat unicast, tapi fungsinya berbeda daripada alamat unicast.
IPv6 menggunakan alamat anycast untuk mengidentifikasikan beberapa interface yang berbeda. IPv6 akan menyampaikan paket-paket yang dialamatkan ke sebuah alamat anycast ke interface terdekat yang dikenali oleh alamat tersebut. Hal ini sangat berbeda dengan alamat multicast, yang menyampaikan paket ke banyak penerima, karena alamat anycast akan menyampaikan paket kepada salah satu dari banyak penerima. Perbandingan Alamat IPv6 dan IPv4
Tabel berikut menjelaskan perbandingan karakteristik antara alamat IP versi 4 dan alamat IP versi 6.
Kriteria Alamat IP versi 4
Alamat IP versi 6
Panjang alamat 32 bit 128 bit
Jumlah total host (teoritis) 232=±4 miliar host 2128
Menggunakan kelas alamat Ya, kelas A, B, C, D, dan E. Template:BrBelakangan tidak digunakan lagi, mengingat telah tidak relevan dengan perkembangan jaringan Internet yang pesat. Tidak
Alamat multicast Kelas D, yaitu 224.0.0.0/4 Alamat multicast IPv6, yaitu FF00:/8
Alamat broadcast Ada
Tidak ada
Alamat yang belum ditentukan 0.0.0.0 ::
Alamat loopback 127.0.0.1 ::1
Alamat IP publik Alamat IP publik IPv4, yang ditetapkan oleh otoritas Internet (IANA) Alamat IPv6 unicast global
Alamat IP pribadi Alamat IP pribadi IPv4, yang ditetapkan oleh otoritas Internet
Alamat IPv6 unicast site-local (FEC0::/48)
Konfigurasi alamat otomatis Ya (APIPA) Alamat IPv6 unicast link-local (FE80::/64)
Representasi tekstual Dotted decimal format notation Colon hexadecimal format notation
Fungsi Prefiks Subnet mask atau panjang prefiks Panjang prefiks
Resolusi alamat DNS
A Resource Record (Single A) AAAA Resource Record (Quad A)
Jaringan adalah sebuah himpunan komputer yang dihubungkan dengan kabel sehingga komputer satu dengan komputer lainnya dapat saling komunikasi, bertukar informasi sharing file, printer, dll.
Jaringan dibagi menjadi 2 yaitu 1. Standalone
2. Network
B. Jenis – Jenis Jaringan Berdasarkan Jangkauan
1. Local Area Networking (LAN)
Yaitu Jaringan yang dibatasi oleh area yang relative kecil, umumnya dibatasi oleh area lingkungan seperti sebuah perkantoran di sebuah gedung, atau sebuah sekolah, dan biasanya tidak jauh dari sekitar 1 km persegi.
2. Metropolitan Area Networking (MAN)
Yaitu Jaringan yang lebih luas dari LAN, MAN biasanya meliputi area yang lebih besar seperti area propinsi, antar gedung. Mengapa MAN itu dikatakan lebih luas dari LAN?, Yah, karena jaringan MAN itu terhubung dari beberapa jaringan LAN yang dihubungkan melalui switch lagi.
3. Wide Area Networking (WAN)
Yaitu Jaringan yang lingkupnya biasanya sudah menggunakan sarana Satelit ataupun kabel bawah laut sebagai contoh keseluruhan jaringan BANK BNI yang ada di Indonesia ataupun yang ada di Negara-negara lain. Menggunakan sarana WAN, Sebuah Bank yang ada di Bandung bisa menghubungi kantor cabangnya yang ada di Hongkong, hanya dalam beberapa menit. Biasanya WAN agak rumit dan sangat kompleks, menggunakan banyak sarana untuk menghubungkan antara LAN dan WAN ke dalam Komunikasi Global seperti Internet.
C.Topologi Jaringan
Topologi Jaringan adalah struktur atau bentuk jaringan.
Jenis – jenis topologi jaringan
a. Topologi Ring
Topologi Ring adalah topologi yang terkoneksi ke dua landcard. Jadi pengiriman datanya berbentuk arah jarum jam dan berlawanan arah jarum jam. Sehingga pengiriman data sering tidak sampai ke komputer yang dituju karena harus melewati komputer yang lain dahulu.
b. Topologi Star
Topologi Star adalah topologi yang mengunakan switch sebagai penghubungan antar kabel jaringa. Jadi, Topologi ini lebih sering digunakan ketimbang topologi yang karena biaya lebih murah dan trasperdata lebih cepat. Karena swicth yang mengatur lajunya data.
c. Topologi Bus
Topologi Bus adalah topologi yang memiki satu kabel yang terhubung ke server jadi komputer yang ingin masuk ke topologi bus harus menyambungkan kabel BNCnya ke kabel BNC server. Karena topologi ini menggunakan kabel BNC.
Basis data terdistribusi ; Secara logik keterhubungan dari kumpulan-kumpulan data yang digunakan bersama-sama, dan didistribusikan melalui suatu jaringan komputer.
DBMS Terdistribusi ; Sebuah sistem perangkat lunak yang mengatur basis
data terdistribusi dan membuat pendistribusian data
secara transparan.
DDBMS memiliki satu logikal basis data yang dibagi ke dalam beberapa fragment. Dimana setiap fragment disimpan pada satu atau lebih komputer dibawah kontrol dari DBMS yang terpisah , dengan mengkoneksi komputer menggunakan jaringan komunikasi.
Masing- masing site memiliki kemampuan untuk mengakses permintaan pengguna pada data lokal dan juga mampu untuk memproses data yang disimpan pada komputer lain yang terhubung dengan jaringan.
Pengguna mengakses basis data terdistribusi dengan menggunakan dua aplikasi yaitu aplikasi lokal dan aplikasi global, sehingga DDBMS memiliki karakteristik yaitu :
·Kumpulan dari data logik yang digunakan bersama-sama
·Data di bagi menjadi beberapa fragment
·Fragment mungkin mempunyai copy ( replika )
·Fragment / replika nya di alokasikan pada yang digunakan
·Setiap site berhubungan dengan jaringan komunikasi
·Data pada masing-masing site dibawah pengawasan DBMS
·DBMS pada masing-masing site dapat mengatasi aplikasi lokal, secara otonomi
·Masing-masing DBMS berpastisipasi paling tidak satu global aplikasi.
Dari definisi tersebut , sistem diharapkan membuat suatu distribusi yang transparan. Basis data terdistribusi terbagi menjadi beberapa fragment yang disimpan di beberapa komputer dan mungkin di replikasi, dan alokasi penyimpanan tidak diketahui pengguna . AdanyaTransparansi di dalam basis data terdistribusi agar terlihat sistem ini seperti basis data tersentralisasi. Hal Ini mengacu pada prinsip dasar dari DBMS (Date,1987b).Transparansi memberikan fungsional yang baik untuk pengguna tetapi sayangnya mengakibatkan banyak permasalahan yang timbul dan harus diatasi oleh DDBMS.
Pemrosesan Distribusi : Basis data tersentralisasi yang dapat diakses di
semua jaringan komputer
Point utama dari definisi basis data terdistribusi adalah sistem terdiri dari data yang secara fisik di distribusikan pada beberapa site yang terhubung denganjaringan.
Jika data nya tersentralisasiwalaupun ada pengguna lain yang mengakses data melewati jaringan , hal ini bukan disebut dengan DDBMSmelainkan pemrosesan secara distribusi.
Paralel DBMSs
DDBMS memiliki perbedaan dengan paralel DBMS.
Paralel DBMSs; Sistem manajemen basis datainimenggunakan beberapa prosesor dan diskyang dirancang untuk dijalankan secara paralel , apabila di mungkinkan, selama hal tersebut digunakan untuk memperbaiki kinerja dari DBMS
Sistem DBMS berbasis pada sistem prosesor tunggal dimana sistem prosesor tunggal tidak memiliki kemampuan untuk berkembang, untuk menghitung skala efektifitas dan biaya, keandalan dan kinerja dari sistem.Paralel DBMS di jalankan olehberbagai multi prosesor. Paralel DBMS menghubungkan beberapa mesin yang berukuran kecil untuk menghasilkan keluaran sebuah mesin yang berukuran besar dengan skalabilitas yang lebih besar dan keandalan dari basis datanya.
Untuk menopang beberapa prosesor dengan akses yang sama pada satu basis data, DBMS paralel harus menyediakan manajemen sumber daya yang dapat diakses bersama. Sumber daya apa yang dapat digunakan bersama, dan bagaimana sumber daya tersebut di implementasikan, mempunyai efek langsung pada kinerja dan skalabilitas dari sistem , hal ini tergantung dari aplikasi atau lingkungan yang digunakan.
Ada tiga arsitektur yang digunakan pada paralel DBMS yaitu :
a.Penggunaan memory bersama ( share memory )
b.Penggunaan disk bersama ( share disk )
c.Penggunaan secara sendiri-sendiri ( share nothing )
Arsitektur pada penggunaan secara sendiri – sendiri ( share nothing )hampir sama denganDBMS terdistribusi,namun pendistribusian data pada paralel DBMS hanya berbasis padakinerja nya saja. Node pada DDBMS adalah merupakan pendistribusian secara geographic, administrasi yang terpisah , dan jaringan komunikasi yang lambat, sedangkannode pada paralel DBMSadalah hubungan dengan komputer yang sama atau site yang sama.
Penggunaan Memori Bersama ( Share Memory ) adalah sebuah arsitekturyang menghubungkan beberapa prosesor di dalam sistem tunggal yang menggunakan memori secara bersama – sama ( gbr 1.3 ). Dikenal dengan SMP (Symmetric Multiprocessing ), metode ini sering digunakan dalam bentuk workstation personal yang mensupport beberapa mikroprosesor dalam paralel dbms,RISC ( Reduced Instruction Set Computer ) yang besar berbasis mesin sampai bentuk mainframe yang besar. Arsitektur ini menghasilkan pengaksesan data yang sangat cepatyang dibatasi oleh beberapa prosesor , tetapi tidak dapat digunakan untuk64 prosesor dimana jaringan komunikasi menjadi masalah ( terjadinya bottleneck).
Penggunaan Disk Bersama ( Share Disk ) adalah sebuah arsitektur yang mengoptimalkan jalannya suatu aplikasi yang tersentrallisasi dan membutuhkan keberadaan datadan kinerja yang tinggi ( Gbr 1.4 ).Setiap prosesor dapat mengakses langsung semua disk , tetapi prosesor tersebut memiliki memorinya sendiri – sendiri. Seperti halnya penggunaan secara sendiri – sendiriarsitektur ini menghapus masalah pada penggunaan memori bersama tanpa harus mengetahui sebuah basis data di partisi. Arsitektur ini di kenal dengan cluster
Penggunaan Secara sendiri – sendiri ( Share nothing ) ;sering di kenal dengan Massively parallel processing ( MPP ) yaitu arsitektur dari beberapa prosesor di mana setiap prosesor adalah bagian dari sistem yang lengkap , yang memiliki memori dan disk ( Gbr 1.5 ).Basis data ini di partisi untuk semua disk pada masing – masing sistem yang berhubungan dengan basis datadan datadi berikan secara transparan untuk semua pengguna yang menggunakan sistem . Arsitektur ini lebih dapat di hitung skalabilitasnya dibandingkan dengan share memory dan dapat dengan mudah mensupport prosesor yang berukuran besar. Kinerja dapat optimal jika data di simpan di lokal dbms.
Paralel teknologi ini biasanya digunakan untuk basis data yang berukuran sangat besar ( terabites ) atau sistem yang memproses ribuan transaksi perdetik. Paralel DBMS dapat menggunakan arsitektur yang diinginkan untuk memperbaiki kinerja yang kompleks untuk mengeksekusi kueri dengan menggunakan paralel scan, join dan teknik sort yang memperbolehkan node dari banyak prosesoruntuk menggunakan bersama pemrosesan kerja yang di gunakan.
Keuntungan dan Kerugian dari DDBMS
Data dan aplikasi terdistribusi mempunyai kelebihan di bandingkan dengan sistem sentralisasi basis data. Sayangnya , DDBMS ini juga memilikikelemahan.
KEUNTUNGAN
Merefleksikan pada bentuk dari struktur organisasinya
Ada suatu organisasi yang memiliki sub organisasi dilokasi yang tersebar di beberapa tempat,.sehingga basis data yang digunakan pun tersebar sesuai lokasi dari sub organisasi berada.
Penggunaan bersama dan lokal otonomi
Distribusi secara geografis dari sebuah organisasi dapat terlihat dari data terdistribusinya, pengguna pada masing-masing site dapat mengakses data yang disimpan pada site yang lain. Data dapat dialokasikandekat dengan pengguna yang biasa menggunakannya pada sebuah site, sehingga pengguna mempunyaikontrol terhadap data dan mereka dapat secara konsekuen memperbaharui danmemiliki kebijakkan untuk data tersebut. DBA global mempunyai tanggung jawab untuk semua sistem. Umumnya sebagian dari tanggung jawab tersebut di serahkan kepada tingkat lokal, sehingga DBA lokal dapat mengatur lokal DBMS secara otonomi.
Keberadaan data yang ditingkatkan
Pada DBMS yang tersentralisasi kegagalan pada suatu site akan mematikan seluruh operasional DBMS. Namun pada DDBMS kegagalan pada salah satu site, atau kegagalan pada hubungan komunikasi dapat membuat beberapa site tidak dapat di akses, tetapi tidakmembuat operasional DBMStidak dapat dijalankan.
Keandalan yang ditingkatkan
Sebuah basis data dapat di replikasi ke dalam beberapa fragmen sehingga keberadaanya dapat di simpan di beberapa lokasi juga. Jika terjadi kegagalan dalam pengaksesan data pada suatu site di karenakan jaringan komunikasi terputus maka site yang ingin mengakses data tersebut dapat mengakses pada site yang tidak mengalami kerusakan.
Kinerja yang ditingkatkan
Sebuah data ditempatkan pada suatu site dimana data tersebut banyak di akses oleh pengguna, dan hal ini mempunyai dampak yang baik untuk paralel DBMS yaitu memiliki kecepatan dalam pengkasesan data yang lebih baik dibandingkan dengan basis data tersentralisasi Selanjutnya, sejak masing-masing site hanya menangani sebagian dari seluruh basis data , mengakibakan perbedaan pada pelayanan CPU dan I/O seperti yang di karakteristikan pada DBMS tersentralisasi.
Ekonomi
Grosch's Law menyatakan daya listrik dari sebuah komputerdihitungmenurutbiayayangdihabiskandari penggunaan peralatannya, tiga kali biaya peralatan, 9 kali nya dari daya listrik . Sehingga lebih murah jika membuat sebuah sistem yang terdiri dari beberapa mini komputer yang mempunyai daya yang sama jika dibandingkan dengan memiliki satu buah super komputer. Oleh karena itu lebih efektif untuk menambah beberapa workstation untuk sebuah jaringan dibandingkan dengan memperbaharui sistem mainframe. Potensi yang juga menekan biaya yaitu menginstall aplikasi dan menyimpan basis data yang diperlukan secara geografi sehingga mempermudah operasional pada setiap situs.
Perkembangan modular
Di dalam lingkungan terdistribusi, lebih mudah untuk menangani ekspansi . Site yang baru dapat di tambahkan ke suatu jaringan tanpa mempengaruhi operational dari site - siteyang ada. Penambahan ukuran basis data dapat di tangani dengan menambahkan pemrosesan dan daya tampung penyimpanan pada suatu jaringan. Pada DBMS yang tersentralisasi perkembangan akan di ikuti dengan mengubah perangkat keras dan perangkat lunak.
KERUGIAN
Kompleksitas
Pada distribusi DBMS yang digunakan adalah replikasinya, DBMS yang asli tidak digunakan untuk operasional, hal ini untuk menjaga reliabilitas dari suatu data. Karena yang digunakan replikasinya maka hal ini menimbulkan berbagai macam masalah yang sangat kompleks dimana DBA harus dapatmenyediakan pengaksesan dengan cepat , keandalan dan keberadaan dari basis data yang up to date . Jika aplikasi di dalam DBMSyang digunakan tidak dapat menangani hal - hal tersebut maka akan terjadi penurunan pada tingkat kinerja , keandalan dan kerberadaan dari DBMS tersebut, sehingga keuntungan dari DDBMS tidak akan terjadi.
Biaya
Meningkatnya kekompleksan pada suatu DDBMS berarti biaya untukperawatan dari DDBMS akan lebih besar dibandingkan dengan DBMS yang tersentralisasi, seperti biaya untuk membuat jaringannya, biaya komunikasi yang berjalan , orang-orang yang ahli dalam penggunaan, pengaturan dan pengawasan dari DDBMS.
Keamanan
Pada DBMS yang tersentralisasi, pengaksesan data lebih terkontrol. Sedangkan pada DDBMS bukan hanya replikasi data yang harus di kontrol tetapi jaringan juga harus dapat di kontrol keamanannya.
Pengontrolan Integritas lebih sulit
Kesatuan basis data yang mengacu pada keabsahan dan kekonsistenan dari data yang disimpan. Kesatuan biasanya di ekspresikan pada batasan, dimana berisi aturan untuk basis data yang tidak boleh diubah. Membuat batasanuntuk integrity, umumnya memerlukan pengaksesan ke sejumlah data yang sangat besaruntuk mendefinisikan batasan tersebut, namun hal ini tidak termasuk di dalam operasional update itu sendiri. Dalam DDBMS, komunikasi dan biaya pemrosesan yang dibutuhkan untuk membuat suatu batasan integrity mungkin tidak diperbolehkan.
HOMOGEN DAN HETEROGEN DDBMS
Sebuah DDBMS dapat di klasifikasikan menjadi homogen dan heterogen. Dalam sistem yang homogen, semua site menggunakan product DBMS yang sama. Dalam sistem heterogen , product DBMS yang digunakan tidak sama, begitu juga dengan model datanya sehingga sistem dapat terdiri dari beberapa model data seperti relasional, jaringan, hirarki dan obyek oriented DBMS.
Sistem homogen lebih mudah di rancang dan di atur. Pendekatan ini memberikan perkembangan yang baik, tidak mengalami kesulitan dalammembuat sebuah site baru pada DDBMS , dan meningkatkan kinerja dengan mengeksploitasikan kemampuan dalam pemrosesan paralel di beberapa site yang berbeda.
Sistem heterogen, menghasilkan beberapa site yang individualdimana mereka mengimplementasikan basis data mereka dan penyatuan data nya di lakukan di tahap berikutnya. Pada sistem ini penterjemahan di perlukan untuk mengkomunikasikan diantara beberapa DBMS yang berbeda. Untuk menghasilkan transparansi DBMS, pengguna harus dapat menggunakan bahasa pemrograman yang digunakan oleh DBMS pada lokal site. Sistem akan mencari lokasi data dan menampilkan sesuai dengan yang diinginkan.
Data yang dibutuhkan dari site lain kemungkinan :
·Memiliki hardware yang berbeda
·Memiliki product DBMS yang berbeda
·Memiliki hardware dan produk DBMS yang berbeda
Jika hardwarenya yang berbeda tetapi produk DBMS nya sama , maka yang akan di ubah adalah kode dan panjang katanya. Jika yang berbeda produk DBMSnya maka akan lebih kompleks lagi karena yang akan di ubah adalah proses pemetaan dari struktur data dalam satu model data yang sama dengan struktur data pada model data yang lain. Sebagai contoh : relasional pada model data relasional di petakan ke dalam beberapa rekord dan set di model data jaringan . Juga diperlukan perubahan pada bahasa queri yang digunakan ( Contoh pada SQL Perintah SELECT di petakan kedalam model jaringan menjadi FIND atau GET ). Jika keduanya yang berbeda, maka dua tipe perubahan ini diperlukan sehingga pemrosesan menjadi lebih kompleks.
Kompleksitas lainnya adalah memiliki skema konseptual yang sama, dimana hal ini di bentuk dari penyatuan data dari skema individualpada konseptual lokal. Untuk mengatasi hal tersebut di gunakan GATEWAY , dimana metode ini di gunakan untuk mengkonversi bahasa pemrograman dan model data di setiap DBMS yang berbeda ke dalam bahasa dan model data relasional .Tetapi metode ini juga memiliki keterbatasan , yang pertama tidak mensupport manjemen transaksi, bahkan untuk sistem yang sepasang. Dengan kata lain metode ini di antara dua buah sistem hanya merupakan penterjemah query. Sebagai contoh , sebuah sistem tidak dapat mengkoordinasikan kontrol konkurensi dan transaksi pemulihan data yang melibatkan pengupdatean pada basis data yang berhubungan. Kedua, metode ini hanya dapat mengatasi masalah penterjemahan queryyang di tampilkan dalam satu bahasa ke bahasa lainnya yang sama.
GAMBARAN SEBUAH JARINGAN
Jaringan ( Networking ) adalahkumpulan dari komputer - komputeryang terhubung dengan suatu garis komunikasi yang digunakan untuk menukar informasi.
Jaringan komputermungkin di klasifikasikan dalam beberapa jenis. Salah satu klasifikasinya adalah menurut jarak yang digunakan untuk menghubungkan beberapa komputer : Jarak pendek ( Local Area Network ) atau jarak jauh ( Wide Area Network ) . Sebuah Local area network (LAN ) digunakan untuk menghubungkan komputer pada suatu site yang sama. Wide area network (WAN)digunakan untuk menghubungkan komputer yang jarak nya lebih jauh. Jenis lain dari Wan yaitu Metropolitan area network ( MAN ) yang biasanya meliputi sebuah kota atau pinggiran kota . Dengan jarak geografi yang luas , hubungan komunikasi pada WAN relatif lebih lambat dan kurang dapat diandalkan dibandingkan dengan LAN. Kecepatan pengiriman datapada WAN biasanya berkisar 33.6 kilobit per detik ( dial up dengan modem ) sampai 45 megabit per detik ( T3 tanpa melalui saluranpribadi ). Kecepatan pengiriman data pada LAN lebih tinggi yaitu 10 megabit per detik ( dengan ethernet ) sampai 2500 megabit per detik( ATM ) dan memiliki keandalan data yang baik . Yang jelas DDBMS yang menggunakan LAN untuk komunikasi akan memberikan waktu respon yang lebih cepat dibandingkan dengan WAN.
Jika di perhatikan cara dari memilih path atau routine, dapat diklasifikasikan jaringan nya dengan point to point atau dengan broadcast.Dalam jaringan point to point, jika sebuah site ingin mengirimkan pesan ke semua site, pesan tersebut harus di pisah – pisahkan ke dalam beberapa pesan. Di jaringan broadcast , semua site mendapatkan semua pesan , tetapi masing –masing pesan memiliki awalan yang menjadi identitas site tujuan sehingga site yang lainnya di abaikan. WAN biasanya menggunakan jenis jaringan point to pointdan LAN menggunakan jenis jaringan broadcast. Ringkasan mengenai jenis karakteristik dari WAN dan LAN di berikan pada tabel 1.1
WAN
LAN
Jarak dapat mencapai ribuan kilometer
Jarak dapat mencapai hingga beberapa kilometer
Hubungan komputer berjauhan
Hubungan komputer yaitu bekerjasama dalam aplikasi terdistribusi
Jaringan diatur olehorganisasi bebas ( menggunakan penghubungan satelit atau line telepon )
Jaringan di atur oleh pemakai sendiri
( menggunakan kabel sendiri )
Kecepatan data sekitar 33.6 Kbit /detik (salurandengan menggunakan modem ) sampai 45 mbit / detik ( T3)
Kecepatan data mencapai 2500 mbit / detik ( ATM )
Protokol rumit
Protokol sederhana
Routing point to point
Routing broadcast
Topologi yang digunakan tidak tentu
Menggunakan topologi BUS atau RING
Tingkat kesalahan 1:105
Tingkat kesalahan 1:109
Tabel 1.1
Ringkasan Karakteristik dari WAN dan LAN
Organisasi internasional untuk standarisasi telah menetapkan sebuah protokol yang mengatur cara agar sebuahsistemdapat berkomunikasi ( ISO,1981) . Pendekatan yang dilakukan adalah dengan membagi jaringan dalam beberapa jenis lapisan. Protokol tersebut di kenal dengan ISOOpen Systems Interconnection Model ( OSI Model ) , yang terdiri dari tujuh pabrikan lapisan independen. Lapisan ini mentransmisi bit yang belum di olah melewati jaringan , mengatur keterhubungan dan memastikan hubungannya bebas dari kesalahan , pengaturan rute atau lintasannya dan kontrol jaringannya, mengatur masalah antara sistem mesin yang berbeda .
PROTOKOL JARINGAN
Protokol jaringan adalah sekumpulan aturan – aturan yang menentukan bagaimana pesan antar komputer dapat terkirim , diterjemahkan dan di proses.
Pada bagian ini diuraikan beberapa gambaran protokol jaringan utama.
TCP/IP ( Transmission Control Protocol / Internet Protocol )
Ini adalah protokol standard komunikasi dalam internet, sekumpulan jaringan komputer di seluruh dunia. TCP memiliki tanggung jawab untuk memeriksa pengiriman data yang benar dari client ke server. IP menyediakan mekanisme routing, berdasarkan pada empat byte alamat tujuan ( alamat IP ). Bagian depan dari alamat IP menunjukan bagian jaringan dari alamatdan bagian belakang menunjukan bagian host dari alamat . Batas pemisah jaringan dengan bagian host dari alamat IP tidak ditentukan . TCP/IP adalah protokol terskema , yaitu semua pesan tidak hanya berisikan alamat dari pos yang di tuju tetapi juga alamat dari jaringan yang dituju . Hal ini mengijinkan pesan TCP/IP di kirim ke banyak jaringan dalam suatu organisasi atau seluruh dunia.
Novell membuat SPX/IPX sebagai bagian dari sistem operasi netware. Hampir sama dengan TCP, SPX menjamin bahwa pesan yang masuk sampai dengan lengkap tetapi menggunakan protokol IPX Netware sebagai mekanisme pengirimannya. Seperti IP , IPX menangani rute paket yang melewati jaringan . Tidak seperti IP, IPX menggunakan 80 bit untuk alamat, dengan 32 bit bagian alamat jaringan dan 48 bitbagian alamat host( hal ini lebih besar dibandingkan dengan yang digunakan pada IP yaitu 32 bit ) IPX tidak menangani paket fragmentasi . Bagaimanapun juga salah satu yang terbaik dari IPX adalah pemberian alamat host yang otomatis. Pemakai dapat memindahkan lokasi jaringan ke tempat yang lain dan melanjutkan pekerjaan dengan mudah dengan menyambungkannya lagi ke jaringan . Ini sangat penting sekali untuk pemakai yang sering berpindah – pindah. Sampai netware 5.0 , SPX/IPX adalah protokol yang digunakan , tetapi untuk menggambarkan betapa pentingnya internet, Netware 5.0 mengangkat TCP/IP sebagai protokol yang digunakan .
NetBIOS (Network Basic Input Output System )
Protokol jaringan dikembangkan pada tahun 1984 oleh IBM dan Sytek sebagai aplikasi standard komunikasi untuk PC. Pada awalnya NetBIOS dan NetBEUI ( NetBIOS dengan pengembangan tampilan pemakai ) telah mempertimbangkan satu protokol . Kemudian NetBIOS banyak digunakan sejak digunakan bersama protokol NetBEUI,TCP/IP, dan SPX/IPX. NetBEUI adalah protokol jaringan yang kecil, cepat dan efisien yang disalurkanbersama produk jaringan microsoft . Bagaimanapun , ini bukan rute skema, jadi konfigurasi khusus dengan menggunakan Net BEUI untuk komunikasi bersama sebuah Lan dan TCP/IP melebihi LAN.
APPC ( Advanced Program to Program Communciation )
Protokol komunikasi tingkat tinggi dari IBM yangmenyediakan sebuah program untuk berinteraksi dengan jaringan lain. Ini dapat mendukung client – server dan memperhitungkan pendistribusian dengan menyediakan pemrograman tampilan biasa pada sebuah platform IBM. Ini di dukung perintah untuk mengatur pembahasan, pengiriman, dan penerimaan data dan manajemen transaksi menggunakan dua tahap pelaksanaannya. Perangkat lunak APPC adalah salah satu bagian atau yangtersedia secara bebas, dalam semua sistem operasi non IBM lainnya. Sejak APPC hanya di dkukung oleh sistem arsitektur jaringan IBM dengan memanfaatkan protokol LU 6.2 untuk membahas pendirian APPC dan LU 6.0 sering kali sama.
DECnet
Decnet adalah protokol rute skema komunikasi digital, DECnet dapat mendukung ethernet tipe LAN dan Baseband dan Broadband WAN meallui saluran pribadi atau publik. Ini terkoneksi dalam PDp, VAX,PC,Mac dan Statiun Kerja.
AppleTalk
Ini adalah rute skema protokol untuk apple yang diperkenalkan tahun 1985, dapat mendukung metode akses percakapan milik apple sebaik ethernet dari token ring. Pengantur jaringan Appletalk dan metode akses percakapan lokasl bersama di bangun MacIntoshs dan Laserwrites
WAP ( Wireless Application Protocol )
Standard digunakan pada telepon seluler, pager dan alamat lain dengan akses keamanan ke email dan halaman web berbasis text. Diperkenalkan pada tahun 1997dengan menggunakan phone.com ( Unwired Planet), Ericson, Motorola dan Nokia, WAP yang menyediakan lingkungan yangbaik untuk aplikasi tanpa kabel yang tersedia dalam rekan wireless dalam TCP /IP dan kerangka kerja untuk persatuan telepon seperti pengontrol panggilan dan akes lihat telepon.
FUNGSI dan ARSITEKTUR DDBMS
Pada bagian ini akan d bahas bagaimana efek dari distribusi suatu basis data untuk fungsi dan pembuatan aristektur DDBMS.
FUNGSI
Dalam bahasan ini, diharapkan pada DDBMS mempunyai paling tidak satu dari fungsional suatu DBMS tersentralisasi. Fungsi – fungsi pada DDBMS yaitu :
1.Memberikan pelayanan komunikasi untuk memberikan akses terhadap site- site yang terhubung baik yang site yang jarak dekat maupun yang letak nya cukup jauh dan mengijinkan pencarian data ke site – site yang terhubung.
2.Memiliki sistem kataloguntuk menyimpan kumpulan detail data yang telah didstribusikan.
3.Mendistribusikan proses pencarian, termasuk optimasisasi dan pengaksesan dari jarak jauh.
4.Memberikan pengendalian keamanan untuk akses ataupun otoritas yang telahdiberikan .
5.Memberikan kontrol konkurensi untuk memelihara data yang telah di replikasi.
6.Memberikan pelayanan recoveri untuk mengambil laporan yang rusak dari setiap site dan kegagalan dalam hubungan komunikasi
Pada ANSI-SPARC ada tiga tingkatan arsitektur dalam DBMS yang dimana arsitektur ini memberikan konstribusi yang banyak untuk arsitektur DDBMS. Perbedaan yang dimiliki oleh DDBMS lebih kompleks / rumit jika dibandingkan dengan arsitektur DBMS. Seperti yang dapat dilihat pada gambar 1.6 yang berisi beberapa tingkatan pada arsitektur DDBMS :
*.Kumpulan tingkatan eksternal global
*. Tingkatan global konseptual
*.Tingkatan fragmentasi dan tingkatan distribusi
*.Kumpulan tingkatan untuk masing – masing DBMS lokal yang
disesuaikan dengan arsitektur pada ANSI-SPARC
Garis dalam gambar tersebut menggambarkan pemetaan antara tingkatan – tingkatan yang cocok dengan tingkat konseptual dalam arsitektur ANSI-SPARC.
Skema Fragmentasi dan Pendistribusian
Skema ini adalah gambaran tentang bagaimana data secara logika di pisah – pisah. Alokasi dari tingkatan ini adalah gambaran tentang ke mana data tersebut akan di simpan dan membuat laporan dari semua penggandaan.
Skema Lokal
Setiap DBMS lokal memiliki skemanya masing -masing . Konseptual lokal dan skema internal pembentukannya sama dengan arsitektur DBMS.Skema pemetaan memetakan fragment – fragment ke dalam alokasi skema kemudian menjadi obyek eksternal pada basis data lokal.Hal ini merupakankemandirian dari suatu basis data dan merupakan dasar untuk mendukung keanekaragaman suatu DBMS.
Arsitektur Federated DBMS
Sistem ini berbeda dengan DDBMS dalam tingkat penyediaan otonomi lokalnya. Hal itu dapat di lihat dari penggambaran arsitekturnya pada gambar 1.7 , dimana pada FDBMS berbentuk tightly coupled dimana pada arsitektur ini terdapat skema global konseptual(SGC)yang merupakan subset dari lokal konseptual skema berisi data dari setiap lokal sistem yang dapat digunakan bersama . GCS dari sistem tightly coupled mempunyai kesatuan data dari setiap skema konseptual dan eksternal nya. Sedangkan pada DDBMS, SGC adalah gabungan dari semua skema konseptual pada setiap lokal sistem.
FDBMS diperdebatkan tidak memiliki skema global konseptual (Liwtin,1988)yang mana sistem ini lebih condong kepada loosely coupleddimana skema eksternal terdiri dari satu atau lebih skema konseptual.
KOMPONEN ARSITEKTUR DDBMS
Pada arsitektur DDBMS terdapat empat komponen utamayaitu :
1.Komponen DBMS lokal
2.Komponen Komunikasi Data (DC)
3.Katalog Sistem Global(GCS)
4.Komponen DDBMS Terdistribusi
Keempat komponen ini dapat di lihat dari gambar 1.8
Komponen Lokal DBMS
Komponen LDBMS ini adalah komponen standard dari DBMS, yang memiliki tanggung jawab untuk mengontrol data lokal pada masing – masing lokasi yang telah memiliki basisdata. Hal ini berarti setiap lokasi memiliki SGC masing – masing yang berisi semua informasi tentang data . Pada sistem homogen komponen LDBMS memiliki produk sistem yang sama yang di replikasi di setiap lokasi. Dan pada sistem heterogen akan ada dua lokasi dengan produk DBMS yang berbeda atau bentuk DBMSnya.
Komponen Komunikasi Data
Komponen ini adalah perangkat lunak dan perangkat keras yang memungkinkan semua lokasi dapat berkomunikasi dengan baik satu sama lain. Komponen komunikasi data berisikan informasi tentang site dan jaringannya.
Katalog Sistem Global ( GCS )
GCS memiliki kesamaan fungsi dengan sistem katalog pada tersentralisasi. GCS menangani informasi yang spesifik mengenai pendistribusian dari suatu sistem, seperti fragmentasi, penggandaan danalokasi nya. Komponen ini dapat mengatur dirinya sendiri seperti mendistribusikan basisdata dan fragmentasi , replikasi keseluruhan atau sentralisasi. Pada GCS yang melakukan replikasi secara keseluruhan menjamin otonomi dari setiap site , seperti melakukan modifikasi harus di beritahukan kepada seluruh site yang terhubung. GCS yang tersentalisasijuga menjanjikan otonomi untuk sitenya dan sangat sensitif terhadap suatu kesalahan pada suatu sitenya.
Pendekatan ini digunakan pada sistem terdistribusi R*(Williams at al,1982). Dalam sistem ini terdapat katalog lokal di setiap site yang terdiri dari meta data yang berhubungan data yang disimpan.Untuk Keterhubungannya disimpan di beberapa site, hal ini merupakan tanggung jawab pada setiap lokal katalog untuk mencatat definisi dari setiap fragmen dan setiap replikas dari setiap fragmen dan mencatat dimana fragment atau replika tersebut di alokasikan. Kapanpun fragmen atau replika di gunakan pada lokasi yang berbeda, lokal katalog harus selalu mengupdate perubahan tersebut, sehingga fragmen atau replika dapat diandalkan keberadaannya.
Komponen DBSM Terdistribusi
Komponen DDBMS adalah pengendalian unit di semua sistem.
Perancangan Relasional Basis Data Terdistribusi
Faktor - faktor yang dianjurkan untuk digunakan pada basis data terdistribusi yaitu :
1.Fragmentasi : Sebuah relasi yang terbagi menjadi beberapa sub-sub relasiyang disebut dengan fragment, sehingga disebut juga distribusi. Ada dua buah fragmentasi yaitu horisontal dan vertikal. Horisontal fragmentasi yaitu subset dari tupel sedangkan vertikal fragmentasi subset dari atribut.
2.Alokasi, setiap fragmen disimpan pada situs dengan distribusi yang optimal.
3.Replikasi, DDBMS dapat membuat suatu copy dari fragmen pada beberapa situs yang berbeda.
Definisi dan alokasi dari fragmen harus berdasarkan pada bagaimana basis data tersebut digunakan.
Perancangan harus berdasarkan kuantitatif dan kualitatif informasi. Kuantitatif informasi digunakan pada alokasi data sedangkan kualitatif informasi digunakan untuk fragmentasi.
Kuantitatif informasi termasuk :
·Seberapa sering aplikasi di jalankan
·Situs mana yang aplikasinyadijalankan
·Kriteria kinerja untuk transaksi dan aplikasi
Kualitatif informasi termasuk transaksi yang dieksekusi pada aplikasi, termasuk pengaksesan relasi, atribut dan tuple , tipe pengaksesan( R atau W ) dan predikat dari operasional.
Definisidan alokasi dari fragment menggunakan strategi untuk mencapai obyektifitas yang diinginkan :
1.Referensi Lokal
Jika memungkinkan data harus disimpan dekatdengan yang menggunakan. Bila suatu fragmen digunakan di beberapa lokasi , akan menguntungkan jika fragmen data tersebut disimpan di beberapa lokasi juga.
2.Reliabilitas dan Availabilitas yang ditingkatkan
Keandalan dan ketersediaan data ditingkatkan dengan replikasi. Ada salinan lain yang disimpan di lokasi yang lain.
3.Kinerja yang di terima
Alokasi yang tidak baik dapat mengakibatkan bottleneck terjadi, sehingga akan mengakibatkan banyaknya permintaan dari beberapa lokasi yang tidak dapat dilayani dan data yang diminta menjadi tidak up to date menyebabkan kinerja turun.
4.Seimbang antara kapasitas penyimpanan dan biaya
Pertimbangan harus diberikan pada ketersediaan infrastruktur dan biaya untuk penyimpanan di setiap lokasi, sehingga untuk efisiensi dapat digunakan tempat penyimpanan yang tidak mahal.
5.Biaya komunikasi yang minimal
Pertimbangan harus diberikan untuk biaya akses jarak jauh.Biaya akan minimal ketika kebutuhan lokal maksimal atau ketika setiap site menduplikasi data nya sendiri. Bagaimanapun ketika data yang di replikasi telah di update. Maka data yang ter-update tersebut harus di duplikasi ke seluruh site, hal ini yang menyebabkan naiknya biaya komunikasi.
Alokasi Data
Ada empat strategis menurut penempatan data : sentralisasi, pembagian partisi, replikasi yang lengkap dan replikasi yang dipilih.
1.Sentralisasi
Strategi ini berisi satu basis data dan DBMS yang disimpan pada satu situs dengan pengguna yang didistribusikan pada jaringan (pemrosesan distribusi). Referensi lokal paling rendah di semua situs, kecuali situs pusat, harus menggunakan jaringan untuk pengaksesan semua data. Hal ini berarti juga biaya komunikasi tinggi.
Keandalan dan keberadaan rendah, kesalahan pada situs pusat akan mempengaruhi semua sistem basis data.
2.Partisi ( Fragmentasi )
Strategi ini mempartisi basis data yang dipisahkan ke dalam fragmen-fragmen, dimana setiap fragmen di alokasikan pada satu site. Jika data yang dilokasikan pada suatu site, dimana data tersebut sering digunakanmakareferensi lokal akan meningkat. Namun tidak akan ada replikasi , dan biaya penyimpanan nya rendah, sehingga keandalan dan keberadaannya juga rendah, walaupun pemrosesan distribusi lebih baik dari pada sentralisasi. Ada satu kelebihan pada sentralisasi yaitu dalam hal kehilangan data, yang hilang hanya ada pada site yang bersangkutan dan aslinya masih ada pada basis data pusat. Kinerja harus bagus dan biaya komunikasi rendah jika distribusi di rancang dengan sedemikian rupa..
3.Replikasi yang lengkap
Strategi ini berisi pemeliharaan salinanyang lengkap dari suatu basis data di setiap site. Dimana referensi lokal, keberadaan dan keandalan dan kinerja adalah maksimal. Bagaimanapun biaya penyimpanan dan biaya komunikasi untuk mengupdate besar sekali biayanya. Untuk mengatasi masalah ini, biasanya digunakan snapshot . Snapshot digunakan untuk menyalin data pada waktu yang telah ditentukan. Data yang disalin adalah hasil update per periode , misalkan per minggu atau perjam, sehingga data salinantersebut tidak selalu up to date. Snapshot juga digunakan untuk mengimplementasikan table view di dalam data terdistribusi untuk memperbaiki waktu yang digunakan untuk kinerja operasional dari suatu basis data.
4.Replikasi yang selektif
Strategi yang merupakan kombinasi antara partisi,replikasi dan sentralisasi. Beberapa item data di partisi untuk mendapatkan referensi lokal yang tinggi dan lainnya, yang digunakan di banyak lokasi dan tidak selalu di update adalah replikasi ;selain dari itu di lakukan sentralisasi. Obyektifitas dari strategi ini untuk mendapatkan semua keuntungan yang dimiliki oleh semua strategi dan bukan kelemahannya. Strategi inibiasa digunakan karena fleksibelitasnya.
FRAGMENTASI
Kenapa harus dilakukan fragmentasi ?
Ada empat alasan untuk fragmentasi :
Kebiasaan ; umumnya aplikasi bekerja dengan tabel views dibandingkan dengan semua hubungan data. Oleh karenanya untuk distribusi data , yang cocok digunakan adalah bekerja dengan subset dari sebuah relasi sebagai unit dari distribusi.
Efisien ; data disimpan dekat dengan yang menggunakan. Dengan tambahan data yang tidak sering digunakan tidak usah disimpan.
Paralel ; dengan fragmen-fragmen tersebut sebagai unit dari suatu distribusi , sebuah transaksi dapat di bagi kedalam beberapa sub queri yang dioperasikan pada fragmen tersebut. Hal ini meningkatkan konkurensi atau paralelisme dalam sistem, sehingga memeperbolehkan transaksi mengeksekusi secara aman dan paralel.
Keamanan ; data yang tidak dibutuhkan oleh aplikasi tidak disimpan dan konsukuen tidak boleh di ambil oleh pengguna yang tidak mempunyai otoritas.
Fragmentasi mempunyai dua kelemahan, seperti yang disebutkan sebelumnya :
Kinerja; cara kerja dari aplikasi yang membutuhkan data dari beberapa lokasi fragmen di beberapa situs akan berjalan dengan lambat.
Integritas; pengawasan inteegritas akan lebih sulit jika data dan fungsional ketergantungan di fragmentasi dan dilokasi pada beberapa situs yang berbeda.
Pembetulan dari fragmentasi
Fragmentasi tidak bisa di buat secara serampangan, ada tiga buah aturan yang harus dilakukan untuk pembuatan fragmentasi yaitu :
1.Kelengkapan ; jika relasi contoh R di dekomposisi ke dalam fragment R1 , R2 ,R3 , … Rn , masing-masing data yang dapat ditemukan pada relasi R harus muncul paling tidak di salah satu fragmen. Aturan ini di perlukan untuk meyakinkan bahwa tidak ada data yang hilang selama fragmentasi
2.Rekonstruksi; Jika memungkinkan untuk mendefinisikan operasional relasi yang akan dibentuk kembali relasi R dari fragmen-fragmen.
Aturan ini untuk meyakinkan bahwa fungsional ketergantungan di perbolehkan .
Penguraian; Jika item data dimuncul pada fragment Ri , maka tidak boleh muncul di fragmen yang lain. Vertikal fragmentasi diperbolehkan untuk aturan yang satu ini, dimana kunci utama dari atribut harus diulanmg untuk melakukan rekonstruksi. Aturan ini untuk meminimalkan redudansi.
Tipe dari Fragmentasi
Ada dua tipe utama yang dimiliki oleh fragmentasi yaituhorisontal dan vertikal , tetapi ada juga dua tipe fragmentasi lainnya yaitu : mixed dan derived fragmentasi .
1.Horisontal fragmentasi ;
Fragmentasi ini merupakan relasi yang terdiri dari subset sebuah tuple . Sebuah horisontal fragmentasi di hasilkan dari menspesifikasikan predikat yang muncul dari sebuah batasan pada sebuah tuple didalam sebuah relasi. Hal ini di definisikan dengan menggunakan operasi SELECT dari aljabar relasional . Operasi SELECT mengumpulkan tuple yang memiliki kesamaan kepunyaan; sebagai contoh, tuple yang semua nya menggunakan aplikasi yang sama atau pada situs yang sama. Berikan relasi R sebuah horisontal fragmentasi yang didefinisikan :
sP ( R )
dimana P adalah sebuah predikat yang berdasarkan atas satu atau lebih atribut didalam suatu relasi.
Contoh : Diasumsikan hanya mempunyai dua tipe properti yaitu tipe flat dan rumah, horisontal fragmentasi dari properti untuk di sewa dari tipe properti dapat di peroleh sebagai berikut :
P1 : stipe = 'Rumah'( properti sewa)
P2; stipe = 'Flat'(properti sewa)
Hasil dari operasi tersebut akan memiliki dua fragmentasi , yang satu terdiri dari tipe yang mempunyai nilai 'Rumah' dan yang satunya yang mempunyai nilai "Flat'.
Fragment P1
Pno
Street
Area
City
Pcode
Type
Rooms
Rent
Cno
Sno
Bno
PA14
16 Holl
Dee
Aber
AB75S
Rumah
6
650
CO46
SA9
B7
PG21
18 Dell
Hynd
Glas
G12
Rumah
4
500
CO87
SG37
B3
Fragment P2
Pno
Street
Area
City
Pcode
Type
Rooms
Rent
Cno
Sno
Bno
PL94
6 Arg
Dee
Aber
AB74S
Flat
4
450
CO67
SL41
B5
PG4
8 Law
Hynd
Glas
G50
Flat
4
400
CO70
SG14
B3
PG16
2 Man
Part
Glas
G67
Flat
3
300
CO90
SG14
B3
Fragmentasi seperti ini mempunyai keuntungan jika terjadi transaksi pada beberapa aplikasi yang berbeda dengan Flat ataupun Rumah.
1.Kelengkapan ; setiap tuple pada relasi muncul pada fragment
P1 atau P2
2. Rekonstruksi ; relasi Properti sewa dapat di rekonstruksi dari fragmentasi menggunakan operasi Union , yakni :
P1 U P2 = Properti sewa
3. Penguraian ; fragmen di uraikan maka tidak ada tipe properti yang mempunyai tipe flat ataupun rumah.
Terkadang pemilihan dari strategi horisontal fragmentasi terlihat jelas. Bagaimanapun pada kasus yang lain, diperlukan penganalisaan secara detail pada aplikasi. Analisa tersebut termasuk dalam menguji predikat atau mencari kondisi yang digunakan oleh transaksi atau queri pada aplikasi. Predikat dapat berbentuk sederhana (atribut tunggal) ataupun kompleks (banyak atribut). Predikat setiap atribut mungkin mempunyai nilai tunggal ataupun nilai yang banyak. Untuk kasus selanjutnya nilai mungkin diskrit atau mempunyai range.
Fragmentasi mencari group predikat minimal yang dapat digunakan sebagai basis dari fragmentasi skema. Set dari predikat disebut lengkap jika dan hanya jika ada dua tuple pada fragmen yang sama bereferensi pada kemungkinan yang sama oleh beberapa aplikasi . Sebuah predikat dinyatakan relevan jika ada paling tidak satu aplikasi yang dapat mengakses hasil dari fragment yang berbeda.
2.Vertikal Fragmentasi
Adalah relasi yang terdiri dari subset pada atribut
Fragmentasi vertikal ini mengumpulkan atribut yang digunakan oleh beberapa aplikasi. Di definisikan menggunakan operasi PROJECT pada aljabar relasional. Relasi R sebuah vertikal fragmentasi di definisikan :
P a1,a2,…an (R)
dimana a1,a2,…an merupakan atribut dari relasi R
contoh :Aplikasi Payroll untuk PT. Dream Home membutuhkan nomor pokok daari Staff( Sno) dan Posisi, Sex, DOB,Gaji dan NIN atribut setiap anggota dari staff tersebut; departemen kepegawaian membutuhkan ; Sno,Fname,Lname, Alamat,Tel_no dan Bno atribut, Vertikal fragmentasi dari
staff untuk contoh ini diperlukan sebagai berikut :
S1 =PSno,posisi,sex,dob,gaji,nin(Staff)
S2 =PSno,Fname,Lname,Alamat,Tel_no,Bno(Staff)
Akan menghasilkan dua buah fragmen , kedua buah fragmen tersebut berisi kunci utama ( Sno ) untuk memberi kesempatan yang aslinya untuk di rekonstruksi. Keuntungan dari vertikal fragmentasi ini yaitu fragmen-fragmen tersebut dapat disimpan pada situs yang memerlukannya. Sebagai tambahan kinerja yang di tingkatkan, seperti fragmen yang diperkecil di bandingkan dengan yang aslinya.
Fragmentasi ini sesuai dengan skema kepuasan pada aturan pembetulan (Correcness Rules):
1.Kelengkapan ; setiap atribut di dalam relasi staff muncul pada setiap fragmen S1 dan S2
2.Rekonstruksi ; relasi staff dapat di rekonstruksi dari fragmen menggunakan operasi natural join , yakni :
S1S2 = Staff
3.Penguraian ; fragment akan diuraikan kecuali kunci utama, karena diperlukan untuk rekonstruksi .
Fragment S1
Sno
Posisi
Sex
DOB
Salary
NIN
SL21
Manager
M
1-oct-60
300000
WK44201B
SG37
Snr Ass
F
10-nov-65
150000
WL43251C
SG14
Deputy
M
24-mar-70
100000
WL22065B
SA9
Assistant
F
20-jan-70
90000
WM53218D
Fragment S2
Sno
Fname
Lname
Alamat
Tel_no
Bno
SL21
John
White
19 TaylorLondon
0171-884-5112
B5
SG37
Ann
Beech
81 George Glasgow
0141-848-3345
B3
SG14
David
Ford
63 Ashby Glasgow
0141-339-2177
B3
SA9
Marie
Howe
2 Elm Abeerdeen
B7
3. Campuran Fragmentasi
Fragmentasi ini terdiri dari horisontal fragmentasi setelah itu vertikal fragmentasi, atau vertikal fragmentasi lalu horisontal fragmentasi.
Fragmentasi campuran ini di definisikan menggunakan operasi SELECT dan PROJECT pada aljabar relasional.
Relasi R adalah fragmentasi campuran yang didefinisikan sbb :
sP (P a1,a2,…an (R)) atauP a1,a2,…an (sP (R))
dimana p adalah predikat berdasarkan satu atau lebih atribut R dan a1,a2,…an adalah atribut dari R
contoh :
Vertikal fragmentasi staff dari aplikasi payroll dan departemen kepegawaian kedalam :
S1 =PSno,posisi,sex,dob,gaji,nin(Staff)
S2 =PSno,Fname,Lname,Alamat,Tel_no,Bno(Staff)
Lalu lakukan horisontal fragmentasi pada fragmen S2 menurut nomor cabang:
S21 =sBno = B3(S2)
S22 =sBno = B5(S2)
S23 =sBno = B7(S2)
Fragment S1
Sno
Posisi
Sex
DOB
Salary
NIN
SL21
Manager
M
1-oct-60
300000
WK44201B
SG37
Snr Ass
F
10-nov-65
150000
WL43251C
SG14
Deputy
M
24-mar-70
100000
WL22065B
SA9
Assistant
F
20-jan-70
90000
WM53218D
Fragment S21
Sno
Fname
Lname
Alamat
Tel_no
Bno
SG37
Ann
Beech
81 George Glasgow
0141-848-3345
B3
SG14
David
Ford
63 Ashby Glasgow
0141-339-2177
B3
Fragment S22
Sno
Fname
Lname
Alamat
Tel_no
Bno
SL21
John
White
19 TaylorLondon
0171-884-5112
B5
Fragment S23
Sno
Fname
Lname
Alamat
Tel_no
Bno
SA9
Marie
Howe
2 Elm Abeerdeen
B7
Dari fragmentasi tersebut akan menghasilkan tiga buah fragmen yang baru berdasarkan nomor cabang. Fragmentasi tersebut sesuai dengan aturan pembetulan.(Correction rules)
Kelengkapan ; Setiap atribut pada relasi staff muncul pada fragmentasi S1 dan S2 dimana setiap tupel akan mencul pada fragmen S1 dan juga fragmen S21 ,S22 dan S23 .
Rekonstruksi ; relasi staff dapat di rekonstruksi dari fragmen menggunakan operasi Union dan Natural Join , yakni: S1(S21 U S22 U S23 ) = Staff
Penguraian ; penguraian fragmen ; tidak akan ada Sno yang akan muncul di lebih dari satu cabang dan S1 dan S2 adalah hasil penguraian kecuali untuk keperluan duplikasi kunci utama.
4. Derived Horisontal Fragmentation
Beberapa aplikasi melibatkan sua atau lebih relasi gabungan. Jika relasi disimpan ditempat yang berbeda, mungkin akan memiliki perbedaan yang siginifikan di dalam proses penggabungan tersebut. Di dalam fragmentasi ini akan lebih pasti keberadaan relasi atau fragmen dari relasi di tempat yang sama.
Derived fragmen : horisontal fragmen yang berdasarkan fragmen dari relasi yang utama
Istilah anak akan muncul kepada relasi yang mengandung foreign key dan parent pada relasi yang mengandung primari key. Derived fragmentasi di jabarkan dengan menggunakan operasi semijoin dari aljabar relasional.
Misalkan relasi anak adalah R dari relasi parent adalah S, maka fragmentasi derived digambarkan sebagai berikut :
RI= RSfL £ I ³ w
Dimana w adalah nomor dari fragmen horisontal yang telah digambarkan pada S dan f adalah atribut join
Contoh :
Suatu perusahan mempunyai aplikasi yang menggabungkan relasi staff dan PropertyForRent secara bersamaan. Untuk contoh ini di asumsikan staff telah terfragmentasi secara horisontal berdasarkan nomor cabang. Jadi data yang berhubungan dengan cabang disimpan di tempat :
S3 =sBno = B3(Stsff)
S4 =sBno = B5(Staff)
S5 =sBno = B7(Staff)
Diasumsikan bahwa properti PG4 diatur oleh SG14. Ini seharusnya berguna untukmenyimpan data propetri yang menggunakan strategi fragmentasi sama. Ini di peroleh dengan menggunakan derived fragmentasi untuk menfragmentasi secara horisontal relasi PropertiForRent berdasarkan nomor cabang :
PI= PropertiForRentstaffno Sf3 £ I ³ 5
Menghasilkan 3 fragmen ( P3,P4 dan P5) . satu terdiri dari proreprti yang diatur oleh staff dengan nomor cabang B3 (P3), yang satunya terdiri dari properti yang diatur oleh staf dengan nomor cabang B5 ( P5) dan yangterakhir terdiri dari properti yang diatur oleh staff dengna nomro cabang B7 (P7) . Akan mudah dilihat skema fragmentasi ini sesuai dengan peraturan fragmentasi.
Fragment P3
Pno
Street
City
Pcode
Type
Rooms
Rent
Cno
Sno
PG4
6Law
Glas
G11
Flat
3
350
CO40
SG149
PG36
2 Mann
Glas
G32
Flat
3
375
C093
SG37
PG21
18 Dell
Glas
G12
House
4
500
CO87
SG37
PG16
5 Nov
Glas
G12X
Flat
4
450
C093
SG14
Fragment P4
Pno
Street
City
Pcode
Type
Rooms
Rent
Cno
Sno
PL94
6 Arg
Lon
NW1
Flat
4
400
CO87
SL41
Fragment P5
Pno
Street
City
Pcode
Type
Rooms
Rent
Cno
Sno
PA14
16Holl
Aber
AB74S
House
6
650
CO46
SA9
5. Tidak Terdapat Fragmentasi
Strategi final adalah tidak memfragmentasikan relasi. Sebagai contoh, relasi cabang hanya mengandung sejumlah update secara berkala . Daripada mencoba untuk menfragmentasikan relasi secara horisontal, misalnya nomor cabang akal lebih masuk akal lagi untuk membiarkan relasi keseluruhan dan mereplikasi relasi cabang pada setiap sisinya.
TRANSPARANSI PADA DDBMS
Definisi dari DDBMS yang telah dijelaskan pada subbab 1.1 menyatakan bahwa sistem seharusnya melakukan distribusi yang transparan kepada pengguna. Detail dari implementasi pengguna tidak perlu mengetahuinya. DDBMS menampilkan banyak level transparan. Semua transparansi berpartisipasi di semua obyek, agar dapat membuat basis data terdistribusi ini dapat sejalan dengan basis data tersentralisasi . Ada 4 macam tipe utama dari transparansi dalam DDBMS yaitu
Transparansi Distribusi
Transparansi Transaksi
Transparansi Kinerja
Transparansi DBMS
1.Transparansi Distribusi
Distribusi transparansi memperbolehkan pengguna untuk mengetahui bahwa basis data sebagi sebuah single logikal entitas. Jika suatu DDBMS memperlihatkan transparansi terdistribusinya, pengguna tidak perlu tahu mengenai fragmentasi dari datanya ataupun locasi dimana data tersebut di simpan.
Ada suatu transparansi yang memperbolehkan pengguna untuk mengetahui apakah data telah terfragmen dan di simpan suatu di lokasi, nama dari transparansi ini yaitu : Pemetaan Transparansi Lokasi( Transparancy Local Mapping ).
Contoh :
S1 =Pstaffno, position,sex,DOB,salary (STAFF)ditempatkan di site 3
Fragmentasi adalah tingkat tertinggi dari distribusi transparansi yang di sediakan oleh DDBMS, sehingga pengguna tidak perlu tahu mengenai data yang di fragmentasikan.Akses basis data berdasarkan pada skema globalnya, sehingga pengguna tidak perlu menspesifik nama fragmen atau lokasi datanya.
Contoh :
Select fname,lname From Staff
Where position =’Manager’;
Ini adalah statement SQL yang harus di tulis pada sistem tersentralisasi.
Transparansi Lokasi
Transparansi lokasi dalam distribusi transparansiberada pada tingkatmenengah . Dengan transparansiini , user mengetahui data tersbut di fragmentasi tidak perlu mengetahui dimana lokasi dari data tersebut.
Contoh :
SELECT fname,lname FROM S21
WHERE Staffno IN (SELECT Staffno FROM S1 WHERE Position=’Manager’)
UNION
SELECT fname,lname FROM S22
WHERE Staffno IN (SELECT Staffno FROM S1 WHERE Position=’Manager’)
UNION
SELECT fname,lname FROM S23
WHERE Staffno IN (SELECT Staffno FROM S1 WHERE Position=’Manager’);
Sekarang di perlukan nama dari fragmen dalam query. Digunakan juga join ( subquery) di karenakan posisi dan fname ataupun lname muncul di beberapa vertikal fragmentasi yang berbeda. Keuntungan utama dari lokasi transparansi adalah basis data dapat secara fisik teroragnisasi tanpa harus mempengaruhi aplikasi yang mengakses basis data tersebut.
Transparansi Replikasi
Sama dengan lokasi transparansi adalah transparansi untuk menggandakan suatu data , maksudnya pengguna tidak mengetahui data telah di fragmentasi . Transparansi ini merupakan akibat dari adanya transparansi lokasi. Bagaimanapun ada kemungkinan untuk tidak memiliki transparansi lokasi tetapi mempunyai replikasi transparansi.
Transparansi Pemetaan Lokal
Ini adalah tingkatan paling rendah pada distribusi transparansi. Dengan transparansi ini , pengguna perlu menspesifikasikan nama fragmen dan lokasi dari data items.
Contoh :
SELECT fname,lname FROM S21 AT SITE 3
WHERE Staffno IN (SELECT Staffno FROM S1 AT SITE 5 WHERE Position=’Manager’)
UNION
SELECT fname,lname FROM S22 AT SITE 5
WHERE Staffno IN (SELECT Staffno FROM S1 AT SITE 5 WHERE Position=’Manager’)
UNION
SELECT fname,lname FROM S23 AT SITE 7
WHERE Staffno IN (SELECT Staffno FROM S1 AT SITE 5 WHERE Position=’Manager’);
Pemberian Nama Transparansi
Setiap item pada basis data yangtelah didistribusikan memiliki nama yang unik. Oleh karena DDBMS memastikan tidak ada dua site yang membuat obyek basis data dengan nama yang sama. Satu solusi dari masalah iniadalah dengan membuat server nama terpusat, dimana alat bantu ini berisi semua nama dari sistem sehingga jika ada yang sama akan dapat terdeteksi.
Namun masalah ini memiliki kendala yaitu :
·Kurangnya kemampuan lokal otonomi
·Masalah kinerja, jika terpusat maka akan terjadi bottleneck
·Rendahnya ketersediaan, jika site pusat gagal , site yang lain tidak dapat membuat obyek basis databyang lain.
Ada solusi alternatifyaitu dengan di gunakannya ‘awalan’ suatu obyek sebagai identifier lokasi yang menciptakan obyek tersebut. Sebagai contoh relasi Branch di buat pada site S1 sehingga obyek tersebut dapat dinamakan S1.Branch. Namun jika ingin mengidentifikasi setiap fragment dan setiap salinan fragment tersebut maka dapat dibuat S1.Branch.F3.C2
Yang mana terdapat 2 salinan dari fragmen 3 pada relasi Branch yang dibuat pada site S1. Namun hal ini akan mengakibatkan kehilangan data pada transparansi terdistribusi.
Pendekatan yang lain dengan menggunakan alias ( sinonim ) untuk masing – masing obyek basis data. Seperti S1.Branch.F3.C2 diketahui sebagaiLocalbranch yang digunakan pengguna pada site S1. DDBMS memiliki tugas untuk memetakan alias mejadi obyek basis data yang sesuai.
Sistem R* yang terdistribusi membedakan antara obyek printname nya dengan system wide-name nya. Printname adalah nama yang pengguna gunakan yang mengacu pada suatu obyek. System wide-name adalah identifier internal yang unik untuk obyek yang dijamin takkan pernah di ganti. System wide-name terdiri dari 4 bagian yaitu :
1.Creator ID – Lokasi identifier yuang unik untuk pengguna yang menciptakan obyek
2.Creator site ID – global identifier yang unik untuk site dimana obyek dibuat
3.Local name – nama yang tidak memnuhi persyaratan untuk obyek
4.Birth-site ID – identifier yang unik untuk site dimana obyek disimpan sebagai contoh, system wide-name :
Merepresentasikan sebuah obyek dengan local name localBranch, diciptakan oleh pengguna Manager di London dan disimpan di site di Glasgow.
2.Transparansi Transaksi
Transparansi ini pada lingkungan DDBMS memastikan bahwa semua transaksi terdistribusi memelihara konsistensi dan integritas basis data terdistribusinya. Transaksi terdistribusi mengakses data yang disimpan lebih dari satu tempat. Setiap transaksi di bagi menjadi beberapa subtransaksi , satu untuk mengakses site yang harus diakses; sebuah subtransaksi di represenstasikan oleh sebuah agent/perwakilan.
Contoh :
Ada sebuah transaksiT yang mencetak nama dari semua staff,dengan menggunakan skema fragmentasi yang di definisikan S1,S2,S22,dan S23 . Substransaksi dapat didefiniskan TS3,TS5, dan TS7 untuk mewakili agen yang berada di lokasi 3, 5 dan 7. Setiap subtransaksi mencetak nama – nama staff di setiap lokasi tersebut.
Time
TS3
TS5
TS7
t1
Begin transaction
Begin transaction
Begin transaction
t2
Read(fname,lname)
Read(fname,lname)
Read(fname,lname)
t3
Print (fname,lname)
Print (fname,lname)
Print (fname,lname)
t4
End_transaction
End_transaction
End_transaction
Kesatuan dari transaksi terdistribusi merupakan dasar dari konsep transaksi, namun DDBMS harus juga menjamin kesatuan dari setiap subtransaksi. Oleh karena itu tidak hanya harus menjamin sinkronisasi dari subtransaksi dengan local transaksi lainnya yang di operasionalkan bersamaan di sebuah lokasi. Tapi juda memastikan sinkronisasi dari subtransaksi – subtransaksi dengan transaksi global yang berjalan secara serempak di lokasi yangsama maupun di lokasi yang berbeda. Transparansi transaksi di dalam sebuah DBMS terdistribusi di lengkapi oleh bagan fragmentasi, bagan pendistribusian dan bagan replikasi.
Transparansi Konkurensi
Transparansi konkurensi dimiliki oleh DDBMS jika hasil dari semua transaksi konkuren ( didistribusi ataupun yang tidak didistribusi ) di laksanakan secara independen atau pun dalam satu waktu dan menjamin data yang dihasilkan konsisten dan terupdate dengan benar, hal ini sesuai dengan prinsip dasar yang dimiliki oleh basisdata tersentralisasi namun ada penambahan dikarenakan bentuk nya DDBMS makaharus menjamin transaksi lokal ataupun global tidak bertentangan satu sama lain. Dengan cara yang sama, DDBMS harus memastikan konsistensi dari semua subtransaksi global.
Replikasi membuat konkurensi menjadi lebih kompleks. Jika salinan dari suatu replikasi data di perbaharui , update terbaru tersebut harus secepatnya di sebarkan ke semua salinan yang ada. Strateginya adalah menyebarkan setiap perubahan data menjadi satu kesatuan operasional data dari sebuah transaksi. Namun, jika salah satu site yang memegang salinan data tidak dapat dicapai ketika pengupdate sedang dilakukan , dikarenakan site ataupun hubungan komunikasinya sedang gagal, maka transaksi di tunda sampai site tersebut dapat dicapai. Jika terdapat banyak salinan item data, kemungkinan transaksi konkurensi akan tidak sukses. Alternatif lain untuk membatasi hal tersebut yaitu dengan melakukan pengupdate data hanya untuk site yang saat itu ada. Strategi selanjutnya memperbolehkan pengupdate-an terhadap salinan data yang tidak dilakukan secara bersamaan, terkadang setelah basis data yang aslinya terupdate. Penundaan untuk mendapatkan kembali konsistensi dari data dapat terjadi antara beberapa detik sampai dengan beberapa jam.
Transparansi Kegagalan
DBMS tersentralisasi memiliki kemampuan untuk pemulihan datayang digunakan jika terjadinya kegagalan dalam bertransaksi. Jenis kegagalanyang dimiliki oleh DBMS tersentralisasi yaitu : sistem crash, kesalahan media, kesalahan perangkat lunak, bencana alam dan sabotase. Pada DDBMS juga memiliki jenis – jenis kegagalan yaitu :
·Kehilangan data
·Kegagalan hubungan komunikasi
·Kegagalan pada site
·Partisi jaringan
DDBMS harus memastikan kesatuan dari global transaksi, artinya memastikan subtransaksi pada global transaksi semua berhasil ataupun dibatalkan. Oleh karena itu DDBMS harus menyamakan transaksi global untuk memastikan semua subtransaksi telah sukses sebelum dicatat BERHASIL / COMMIT.
Klasifikasi Transaksi
Sebelum menyelesaikan penjelasan mengenai transaksi, akan dijelaskan secara singkat mengenai klasifikasi transaksi yang telah didefinisikan pada IBM arsitektur basis datarelasional terdistribusi ( DRDA ). Pada arsitektur ini ada empat tipe transaksi , setiap tingkatan mempunyai penambahan pada kompleksitasnya di dalam interaksi dengan DBMS
1.Permintaan akses jarak jauh
Aplikasi di satu lokasi dapat mengirimkan permintaan ( perintah (SQL ) ke beberapa lokasi yang jauh untuk mengeksekusi kiriman data tersebut.Permintaan di eksekusi secara keseluruhan pada lokasi tersebut dan dapat menjadi data acuan dilokasi yang jauh tersebut.
2.Satuan kerja jarak jauh ( Remote Unit of Work )
Suatu aplikasi di satu lokasi dapat mengirimkan semua perintah SQL di dalam satuan unit kerja ( transaksi) ke beberapa lokasi yang jauh untuk pelaksanaanya. Semua perintah SQL dieksekusi seluruhnya di lokasi yangjauh dan hanya menjadi data acuan di lokasi tersebut. Namun site lokal yang memutuskan mana transaksi yang akan di commit dan mana yang akan di rollback.
3.Satu kerja distribusi
Aplikasi di satulokasi dapat mengirimkan sebagian atau seluruh permintaan ( perintah (SQL ) di dalam suatu transaksi ke satu atau lebih lokasi yang jauh untuk mengeksekusi kiriman data tersebut.Permintaan di eksekusi secara keseluruhan pada lokasi tersebut dan dapat menjadi data acuan dilokasi yang jauh tersebut.
4.Permintaan Terdistribusi
Suatu aplikasi di suatu lokasi dapat mengirimkan sebagian atau seluruh permintaan ( perintah (SQL ) di dalam suatu transaksi ke satu atau lebihlokasi yang jauh untuk mengeksekusi kiriman data tersebut.Namun, perintah SQL membutuhkan akses data dari satu atau lebih lokasi ( perintah SQL perlu dapat join atau union suatu relasi / fragmen yang berada di lokasi yang berbeda)
3.TRANSPARANSI KINERJA
Transparansi ini membutuhkan DBMS untukmenjadi seperti DBMS terpusat. Di dalam lingkungan terdistribusi, suatu sistem tidak harus mengalami penurunan selama melakukan arsitektur terdistribusi, sebagai contoh munculnya jaringan. Transparansi ini membutuhkan DBMS untuk membuat strategi agar dapat menghemat biaya yang dikeluarkan untuk melakukan suatu permintaan.
Didalam suatu DBMS tersentralisasi, query processor ( QP ) harus mengevaluasi setiap permintaan data dan melaksanakan strategi yang optimal, yang terdiri dari suatu urutan operasionalyang diperintah pada basis data. Didalam suatu lingkungan terdistribusiDistribusi query prosessor ( DQP ) memetakan suatu permintaan data ke dalam suatu urutan operasi yang diperintahkan pada basis data lokal . Hal ini memiliki penambahan kompleksitas untuk mengaksesnya ke dlaam perhitunganfragmentasi, replikasi dan alokasi skema. DQP harus memutuskan :
·Fragmen mana yang akan diakses
·Salinan dari fragmen yang mana yang akan digunakan jika
fragmen akan di replikasi
·Lokasi mana yang akan digunakan
DQP membuat suatu strategi pelaksanaan yang optimal dengan menjalankan beberapa fungsi biaya. Secara umum, biaya – biaya yang berhubungan dengan suatu permintaan terdistribusi termasuk:
·Biaya waktu akses ( I/O) melibatkan pengaksesn dalam data fisik pada disk
·Biaya waktu CPU pada saat melaksanakan operasi – operasi data dalam memori utama
·Biay akomunikasi dengan transmisi data melalui jaringan.
Faktor pertama adalah satu – satunya hal yang dipertimbangkan dalam suatu sistem tersentralisasi . Pada lingkungan terdistribusi, DDBMS harus menghitungbiaya komunikasi, yang paling dominan dalam WAN dengan suatu bandwitdh untuuk golongan kecil kilobyte per detik . Pada kasus seperti itu, optimasi mungkin mengabaikan I/O dan biaya CPU. Namun, LAN mempunyai bandwidth tidak mungkin mengabaikan I/O dan biaya CPU seluruhnya.
Satu pendekatan untuk optimasi query memperkecil biaya total untuk waktu yang akan terjadi di dalam pelaksanaan queri ( Sacco dan Yao,1982). Sebagai pendekatan alternatif ini dapat memperkecil waktu respon queri, di dalam kasus DQP Terkadang waktu respon akan signifikan menjadi lebih kecil dari biaya waktu total.
DATES’S 12 ATURAN UNTUK DDBMS
Pada bagian terakhir ini , akan di jelaskan mengenai dua belas atuarn mengenai DDBMS (Date,1987b). Dasar dari aturan ini adalah bahwa suatu DBMS terdistribusi harus dapat seperti DBMS non distribusi terhadap pengguna. Aturan ini serupa dengan dua belas aturan CODD untuk sistem relasional .
Prinsip dasar : Suatu sistem DDBMS harus terlihat seperti DBMS non distribusi untuk penggunanya.
Otonomi Lokal
Tempat dalam sistemterdistribusi sudah harus otonom. Otonomi berarti :
a.Data lokal adalah miliki DBMS lokal dan di atur sendiri oleh DBMS Lokal
b.Operasi lokal tetap merupakan lokal operasional
c.Semua operasi yang telah diberikan dikontrol oleh DBMS Lokal
Tidak adanya campur tangan site pusat
Semua proses pelayanan, manajemen transaksi , pendekteksian deadlock , optimasi queri dan manajemen dari sistem katalog adalah tanggung jawab dari lokal DBMS, dan pusat tidak memiliki wewenang untuk melakukan hal tersebut.
Operasi yang berkelanjutan
Fungsi dari DDBMS yaitu adanya perkembangan modular dimana jika terjadi suatu ekspansi jaringan maka proses pembuatan infrastruktur tidak akan mengganggu jalannya operasional suatu data.
Lokasi yang mandiri
Kebebasan lokasi sama dengan transparansi lokasi , pengguna bisa mengakses basis data dari banyak tempat. Dalam pengaksesan data tersebut semua data seolah –olah disimpan dekat dengan lokasi pengguna, bukan menjadi masalah tempat dimana data disimpan secara fisik.
Kebebasan Fragmentasi
Pengguna dapat mengakses basis data tanpa harus mengetahui bagaimana data tersebut di fragmen.
Kebebasan replikasi
Pengguna tidak harus mengetahui apakah data telah direplikasi atau tidak dan tidak harus mengaksessuatu salinan tertentu dari item data secara langsung , juga pada saat pengguna melakukan pembaharuan data haruslah detail untuk semua data.
Pemrosesan query terdistribusi
Sistem harus dapat menangani pemrosesan queri yang mereferensi ke suatu data di sejumlah site yang terhubung.
Pemrosesan transaksi terdistribusi
Sistem harus mendukung sebuah transaksi sebagai sebuah unit dari suatu pemulihan data ( recovery) . Dan menjamin bahwa global ataupun lokal transparansi harus sesuai dengan aturan ACID untuk transaksi, contohnya : penamaan, konsistensi, isolasi dan ketahanan ( Automicity,Consistent, Isolation, Defence).
Kebebasan perangkat keras
DDBMS harus dapat digunakan di berbagai macam platform perangkat keras.
10.Kebebasan sistem operasi
Sesuai dengan aturan sebelumnya , maka DDBMS juga harus dapat digunakan di berbagai macam platform system operasi.
11.Kebebasan jaringan
Sama halnya dengan aturan sebelumnya , DDBMS harus dapat digunakan di berbagai macam platform jaringan komunikasi yang berbeda.
12.Kebebasan database
DDBMS di bentuk dari local DBMS yang berbeda, yang memungkinkan adanya model data yang berbeda. Dengan kata lain DDBMS harus dapat mendukung adanya system heterogen.
Keempat aturan terakhir haruslah dimiliki oleh DDBMS. Selebihnya adalah aturan yang umumdan jika ada kelemahan dari standard komputer dan arsitektur jaringannya, sistem hanya dapat mengharapkan darivendor untuk pemenuhan di masa depan.